Engineering notes from the agent era
Most posts here are about what changes when the agent becomes a first-class collaborator: local code intelligence, testing systems that analyze behavior over time, knowledge tooling that compounds. The rest of the career (cloud, low-latency, mobile) shows up when something's worth writing down.
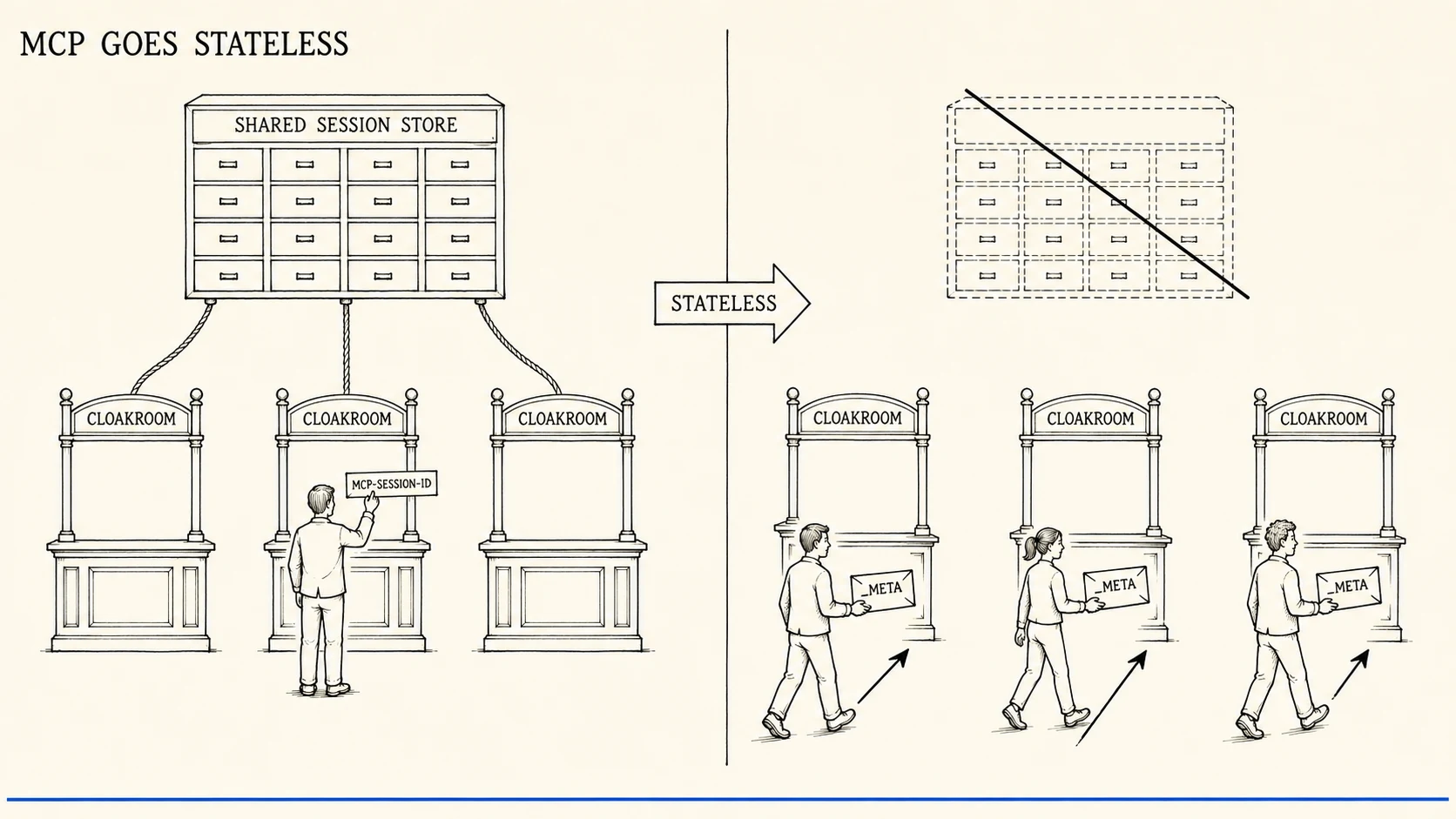
MCP Goes Stateless: The Migration Guide for Shipped Servers
MCP 2026-07-28 removes the handshake, the session id, and Sampling. Nothing breaks on July 28, which is the trap. Here is the migration, in blast-radius order.
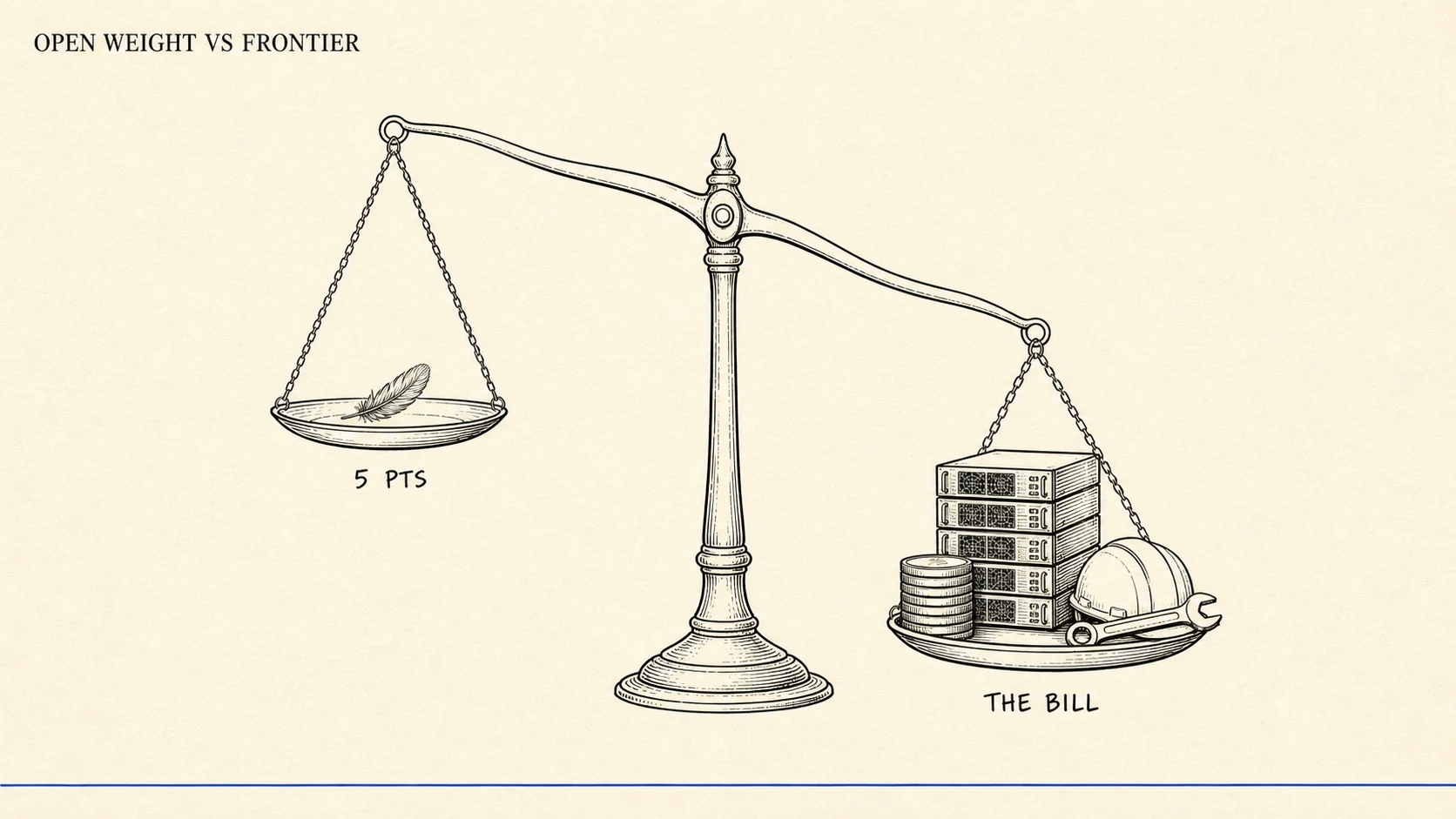
Open Weight vs. Frontier: A Realistic 2026 Coding Verdict
Open-weight coders closed the gap to 5-10 points at a fraction of the price. But they ran 29% of tokens at under 4% of spend in 2026. Route, don't switch.
- open weight
- frontier models
- LLM cost
- self-hosting
- AI engineering
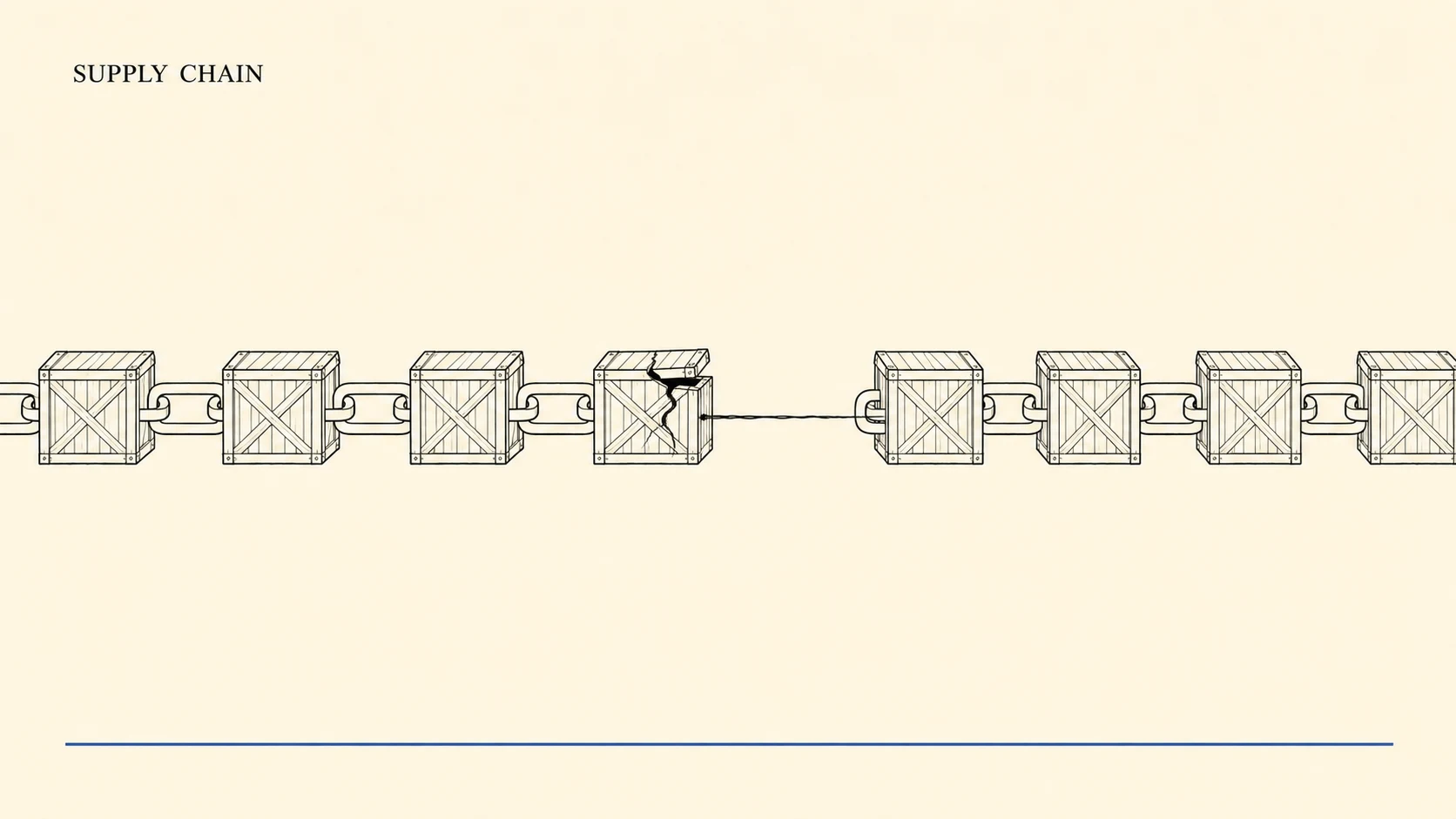
Your Agent's Tools Are a Supply Chain Now
A malicious MCP package ran clean for 15 releases, then a line BCC'd every email to an attacker. Agent tools are a supply chain. Secure them at install time.
- MCP
- supply chain security
- AI agents
- AI security
- prompt injection
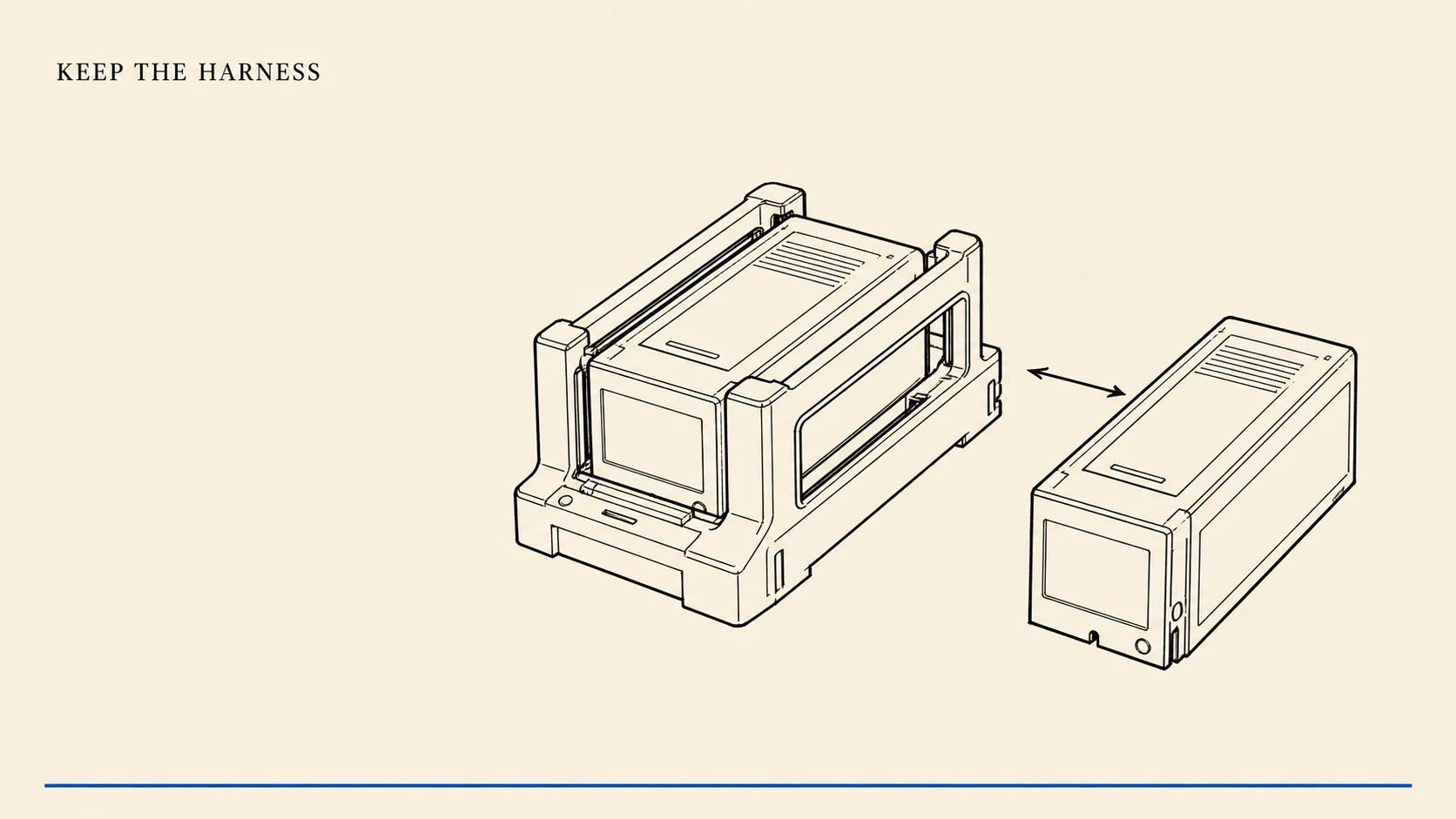
Keep the Harness, Change the Model: Run GPT Inside Claude Code
Keep Claude Code's tools, hooks, skills, MCP servers, and permissions while routing its agent harness to supported GPT models through a local proxy.
- Claude Code
- GPT
- AI coding agents
- developer tools
- model routing
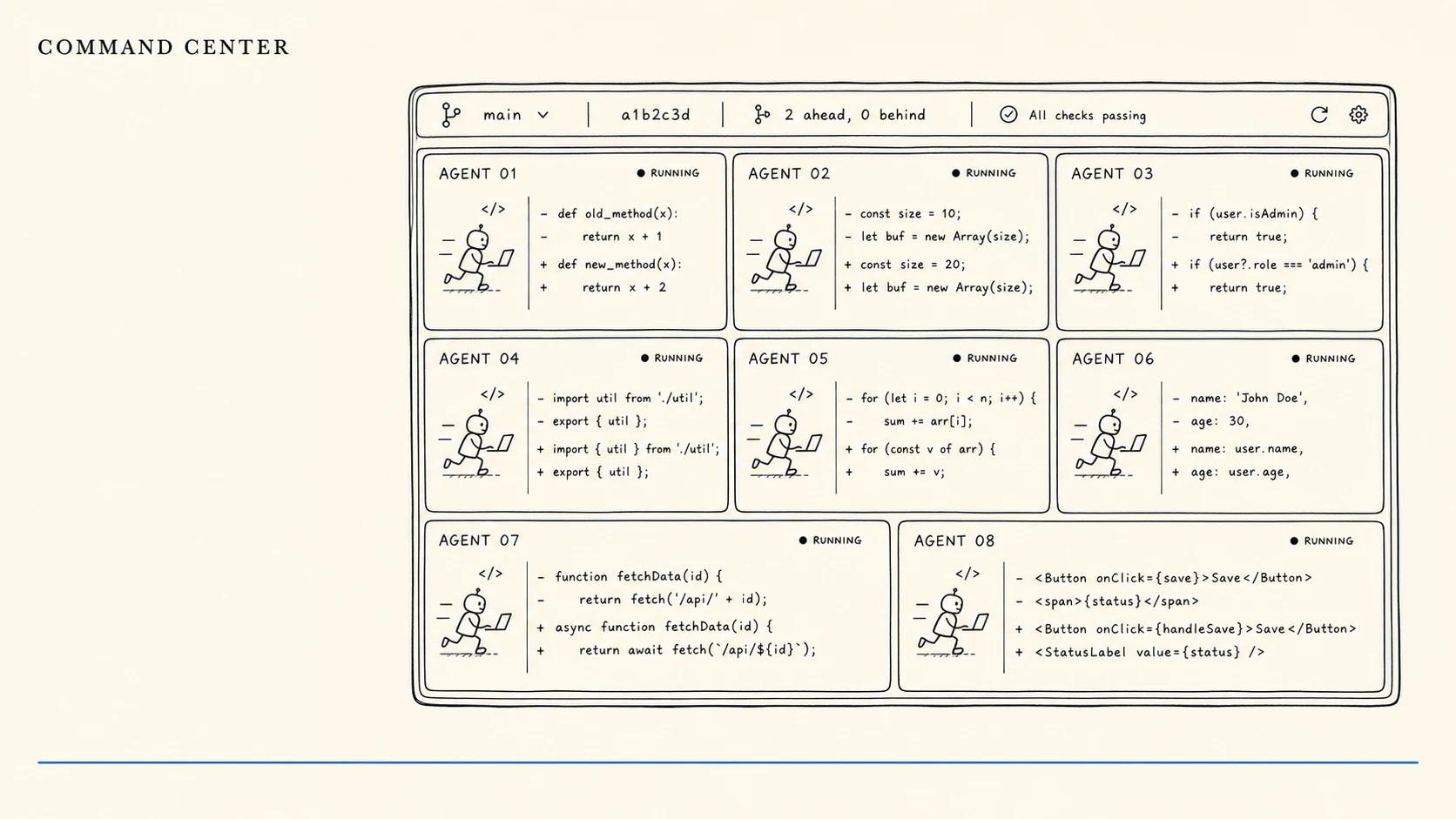
The Year the Coding UI Stopped Being a Text Box
In four months of 2026, six coding tools shipped the same parallel-agent command center. With Codex past 5M weekly users, the UI stopped being anyone's moat.
- AI coding tools
- Codex
- Claude Code
- agentic coding
- developer tools
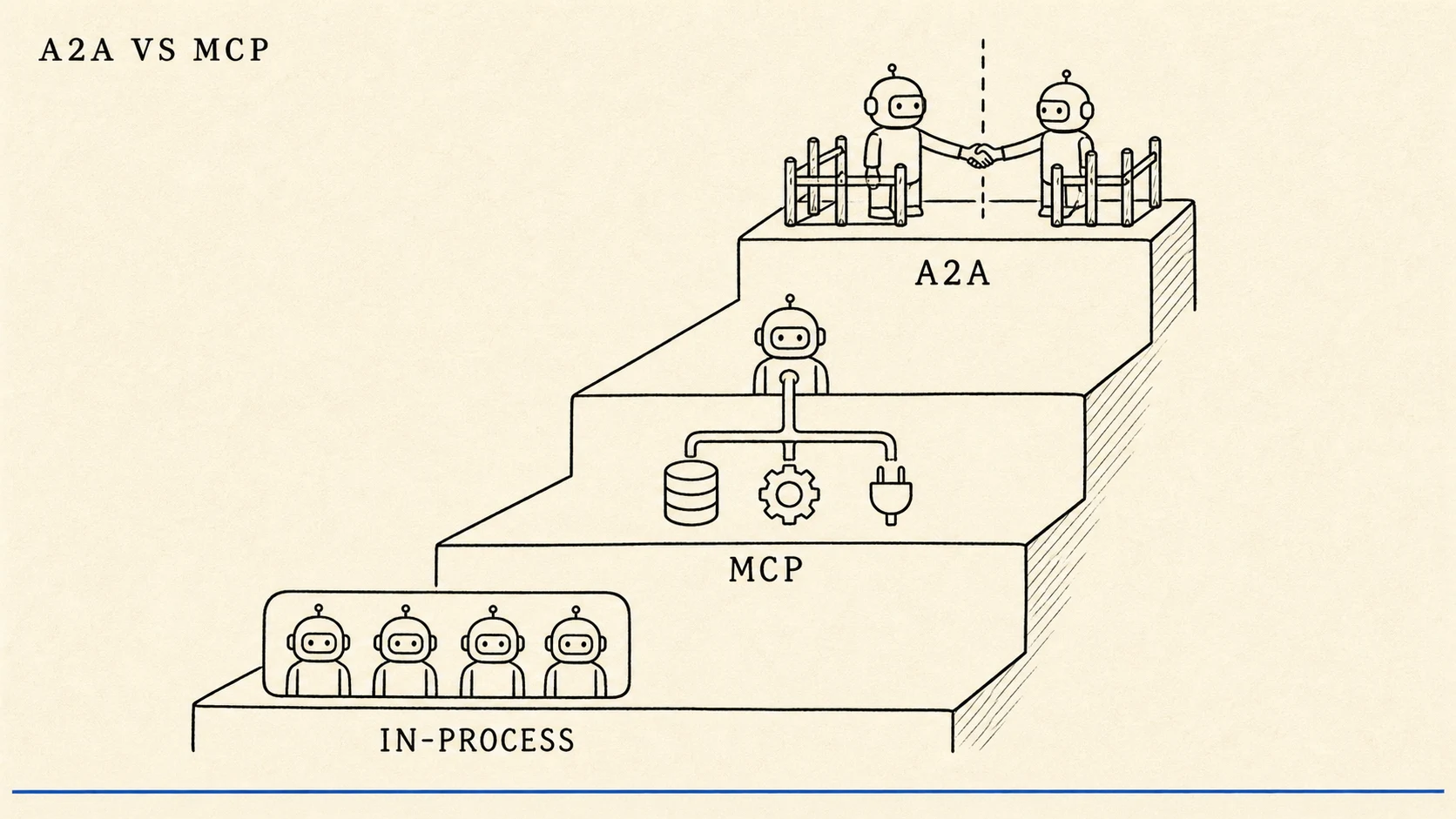
A2A vs. MCP: The Coordination Layer You Haven't Needed Yet
MCP crossed 97M monthly downloads; A2A hit 150+ orgs in a year. But most teams reaching for A2A just need in-process orchestration. Here's the decision tree.
- A2A
- MCP
- AI agents
- multi-agent systems
- platform engineering
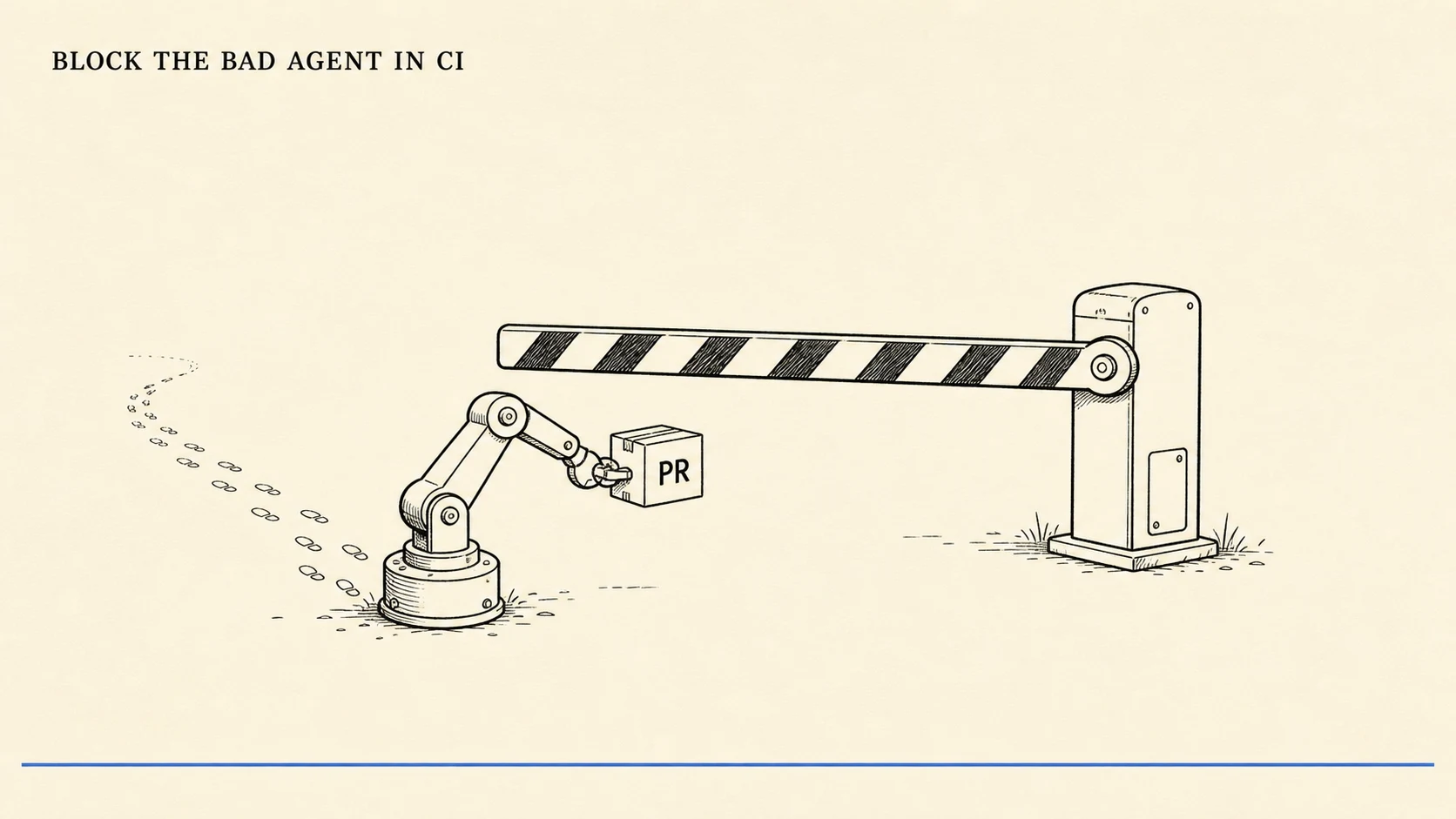
Block the Bad Agent in CI: Gate on Trajectories, Not Just Outputs
More than 1 in 5 GitHub code reviews now involve an agent. Pass@1 is the wrong merge gate. Gate on the trajectory, with a flake budget. Here is the CI policy.
- agent evals
- CI/CD
- agent PR review
- trajectory evaluation
- AI agents
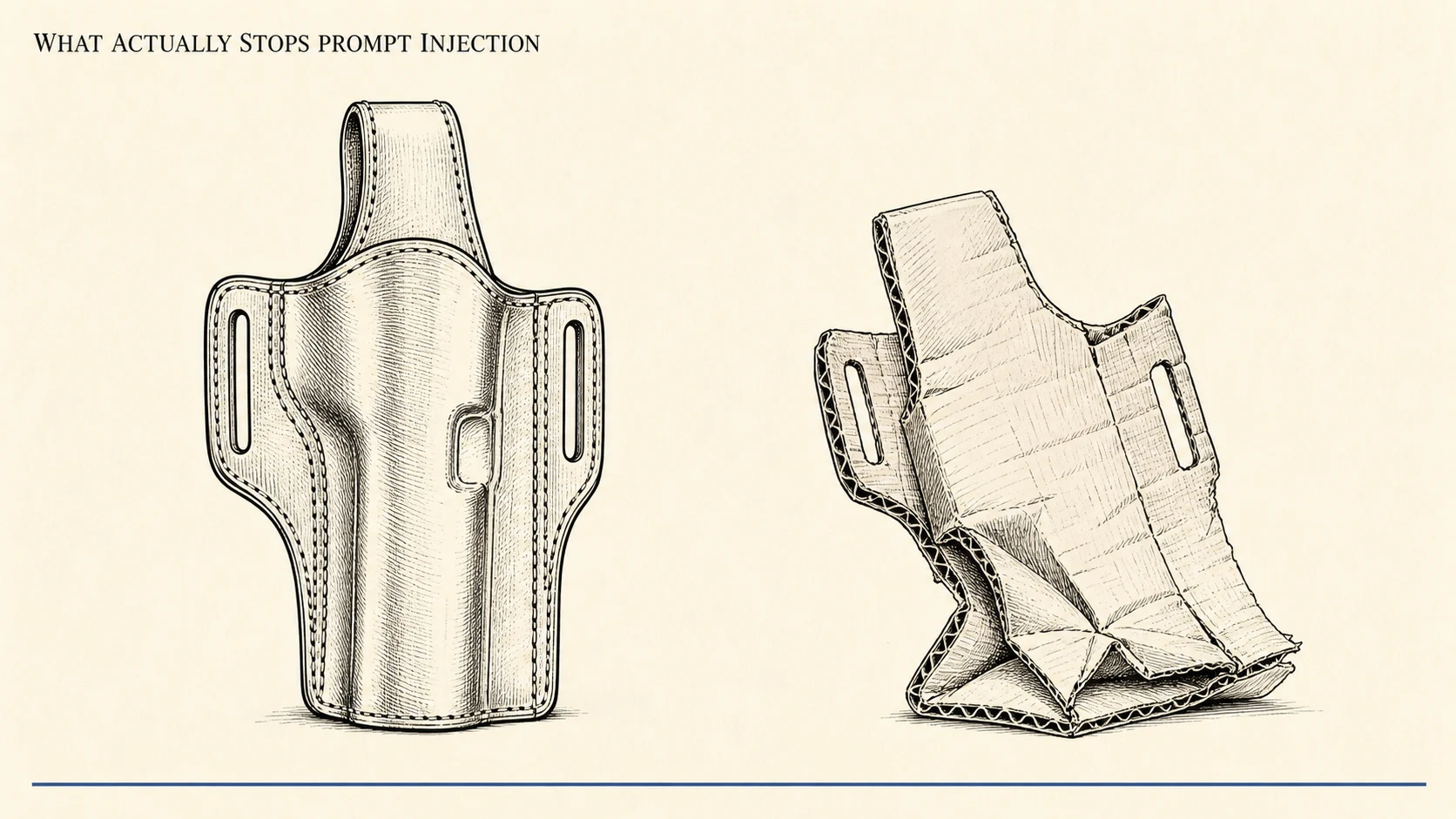
What Actually Stops Prompt Injection: Defenses vs. Theater
A 2026 lab study bypassed 12 prompt-injection defenses at over 90% attack success. Detection is theater; the durable wins are architectural. Here is what holds.
- prompt injection
- AI agent security
- prompt injection defenses
- CaMeL
- AI agents

Narcissus at the Keyboard
Sycophancy is structural, not a bug: models are trained to reflect you back. Why a mirror can't be a collaborator, and how to build the friction back in.
- AI sycophancy
- RLHF
- AI agents
- coding agents
- LLM evaluation
Benchmarks Stopped Measuring Intelligence. Evaluate Models Yourself.
The same model scores 80.9% on SWE-bench Verified and 45.9% on contamination-resistant Pro. A leaderboard number isn't a capability. Build your own eval.
- LLM evaluation
- AI benchmarks
- SWE-bench
- LLM-as-judge
- model selection

The Lethal Trifecta: Why Your Coding Agent Is a Loaded Gun
Four AI products leaked private data to prompt injection in eight days, and attacks top 85% against the best defenses. The lethal trifecta is buildable.
- prompt injection
- MCP security
- lethal trifecta
- AI agents
- indirect prompt injection
LLM-as-Judge Is the New Flaky Test
A 2026 RAND harness found no LLM judge is uniformly reliable; trivial rewrites flip verdicts. Here is the discipline that makes a green eval trustworthy.
- LLM-as-judge
- AI evaluation
- benchmarks
- SWE-bench
- AI agents
The Router Pattern: When to Downshift the Model
A 5-25x cost spread separates Haiku from Opus, yet most agent turns pay top-tier rates. A per-call routing decision tree, and where downshifting breaks.
- AI agents
- model routing
- LLM cost
- Claude Code
- agent pipelines
Sandboxing Coding Agents: The 9-Second Argument for Isolation
A Cursor agent deleted PocketOS's prod database and backups in 9 seconds. Prompt rules aren't a boundary; the kernel is. An isolation ladder for coding agents.
- AI agents
- sandboxing
- security
- Claude Code
- DevOps
Does Your CLAUDE.md Actually Help? The Research Says Maybe Not
An ETH Zurich study found context files cut coding-agent success up to 2% and raised cost 20-23%. Field data disagrees. When your CLAUDE.md earns its tokens.
- Claude Code
- AGENTS.md
- context engineering
- AI agents
- developer productivity
The Session Handoff: When Your Attention Budget Is Spent
Anthropic frames context as an attention budget. Lost-in-the-middle costs 30%+ retrieval accuracy. Three axes of handoff, five triggers, one cut.
- AI agents
- context engineering
- Claude Code
- session handoff
- attention
Agent SRE: Oncall and Escalation for Coding Agents
Anthropic's Apr 23 2026 postmortem took 6 weeks to detect. Five SRE primitives map to Claude Code hooks and turn agent oncall into a shipped artifact.
- AI agents
- SRE
- oncall
- Claude Code
- hooks
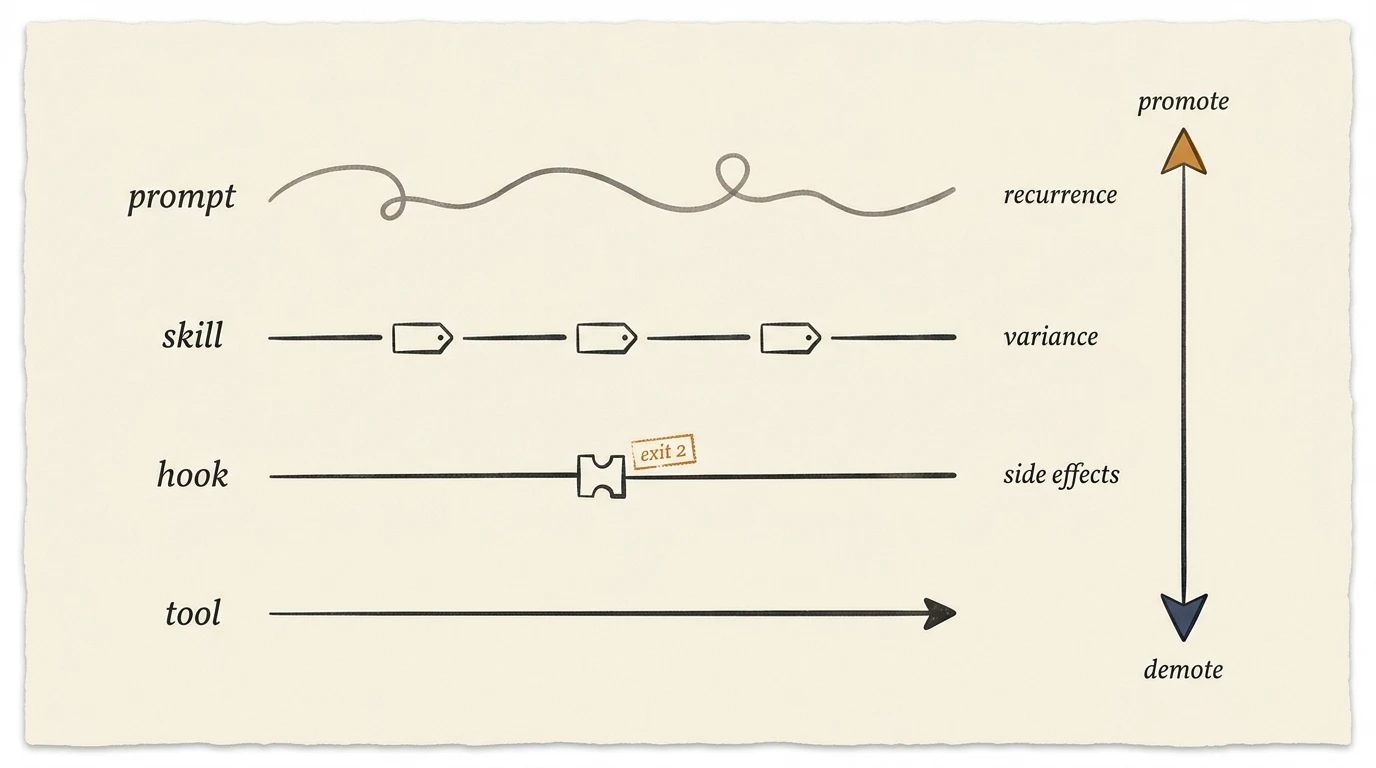
The Promotion Ladder: Prompt, Skill, Hook, Tool
Four rungs trade flexibility for determinism. AGENTIF puts the best model at under 30% adherence; well-designed schema cuts MCP cost 99.9%. Match the rung.
- skills
- hooks
- mcp
- agents
- claude-code
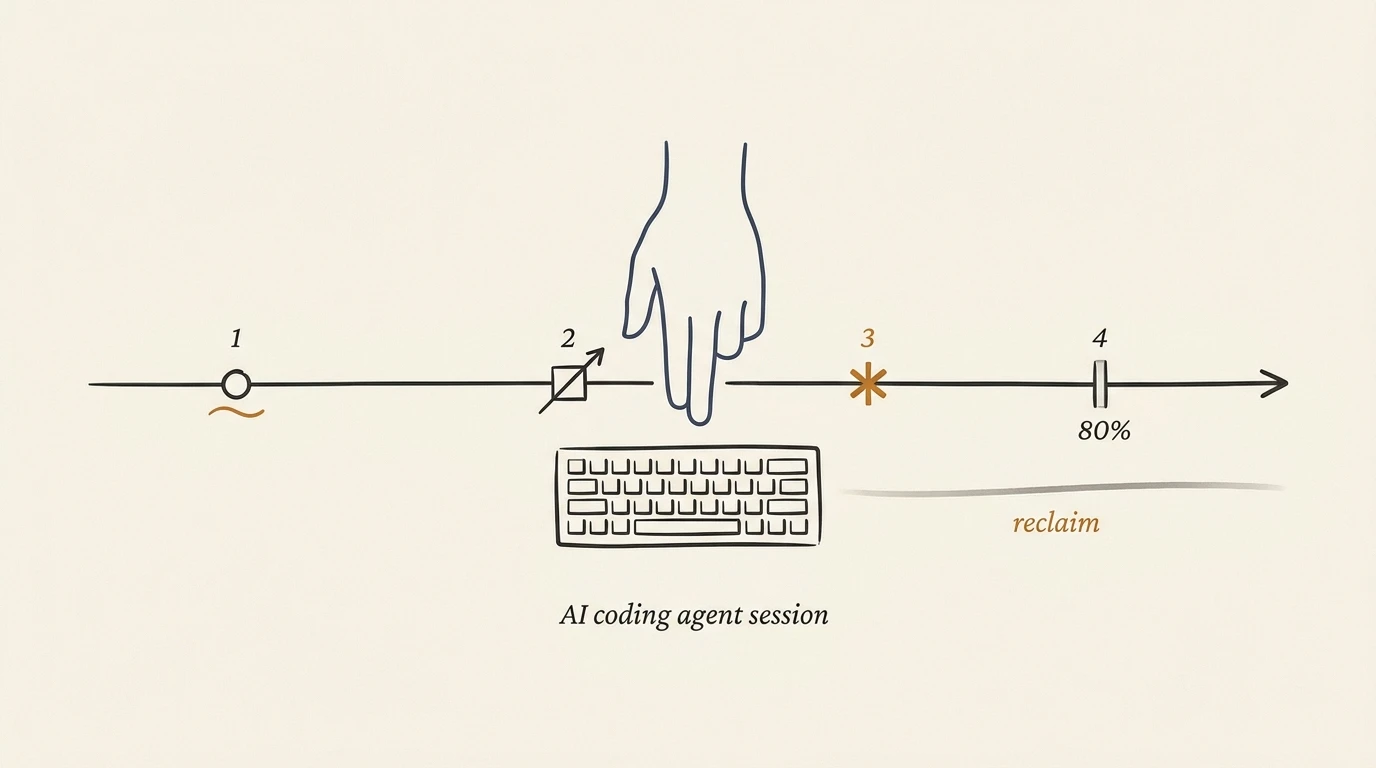
The Handoff Problem: When to Take the Keyboard Back
Developers use AI in 60% of work but fully delegate only 0 to 20% of tasks. Four named cues for the moment you reclaim: drift, scope, novel error, 80%.
- autonomy
- agents
- claude-code
- AI pair programming
- agentic coding

Long-Running Autonomous Agents: Drift, Checkpointing, Recovery
METR pegs Opus 4.6 at a 14.5-hour 50%-time-horizon. Pass@1 collapses 24 points on long tasks. Drift as eval, checkpoint on threshold, fork not restart.
- AI agents
- Claude Code
- agent reliability
- long-horizon agents
- agentic coding

Cache-Aware Prompting: Engineering for 90%+ Hit Rate
ProjectDiscovery moved from 7% to 84% cache hit rate without changing the model. The discipline, the workload taxonomy, the five named failure modes.
- AI engineering
- prompt engineering
- developer productivity
- Anthropic
- cost optimization
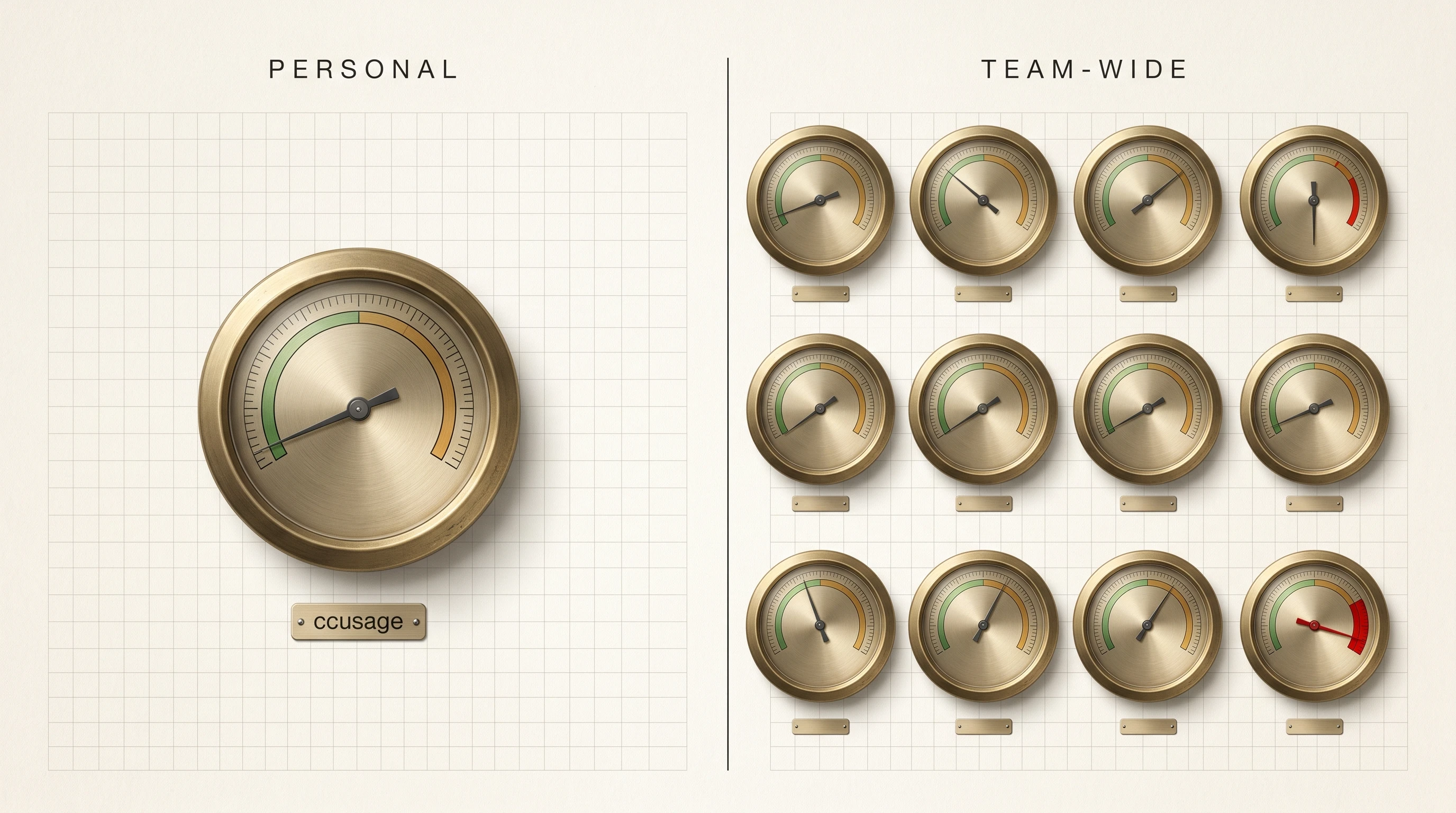
Agent Cost Observability: From Personal Token Budget to Team-Wide
98% of FinOps teams now manage AI spend, up from 31% in 2024. Solo ccusage solved one developer; here is the three-axis, two-cap recipe for 200.
- FinOps
- AI engineering
- developer productivity
- observability
- platform engineering
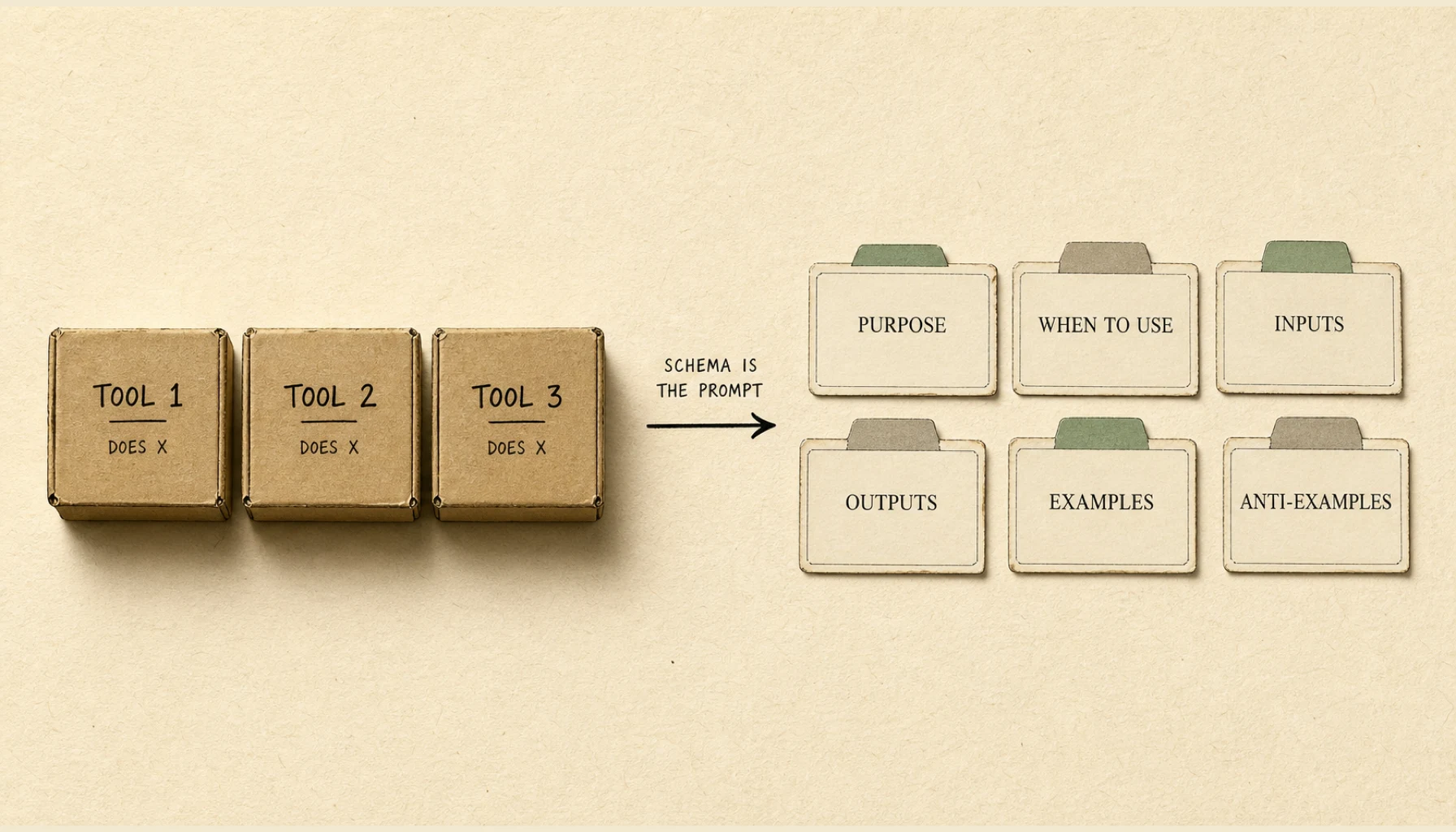
Tool Design for Agents: Schema Is the Prompt
97% of MCP tool descriptions have at least one code smell. 56% fail to state purpose. The description is the prompt your agent reads to pick a tool. Here is the rubric.
- AI agents
- MCP
- developer tools
- prompt engineering
- platform engineering
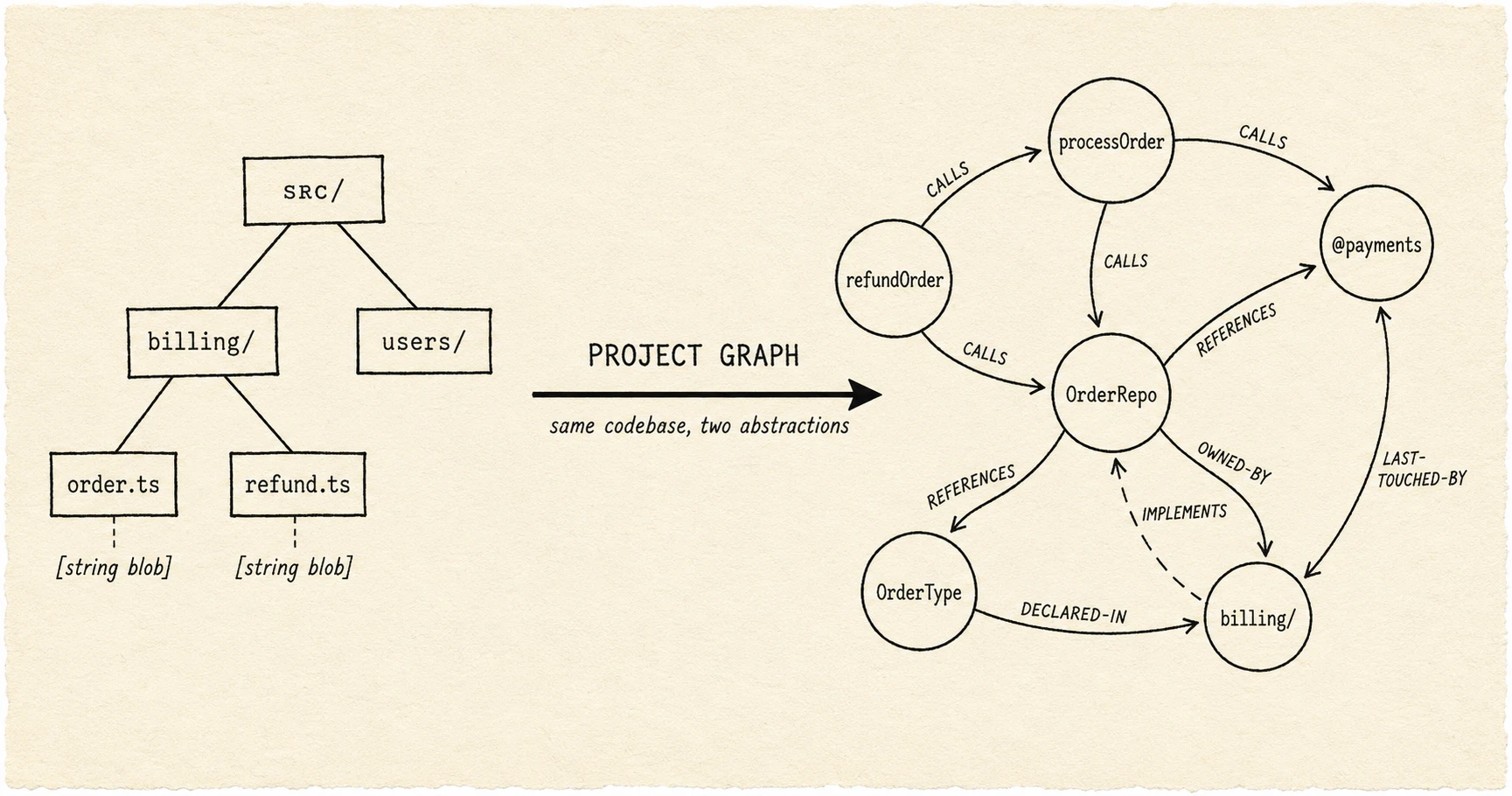
The Project Graph: What Agents Need That Filesystems Can't Give
40 questions, two large repos, three LLM judges. Code-intelligence: judge 7.12 vs default 6.30 (+0.82), 29% faster, +8% tokens. Cites 50% vs CodeGraph's 32%.
- AI agents
- developer tools
- MCP
- code intelligence
- platform engineering
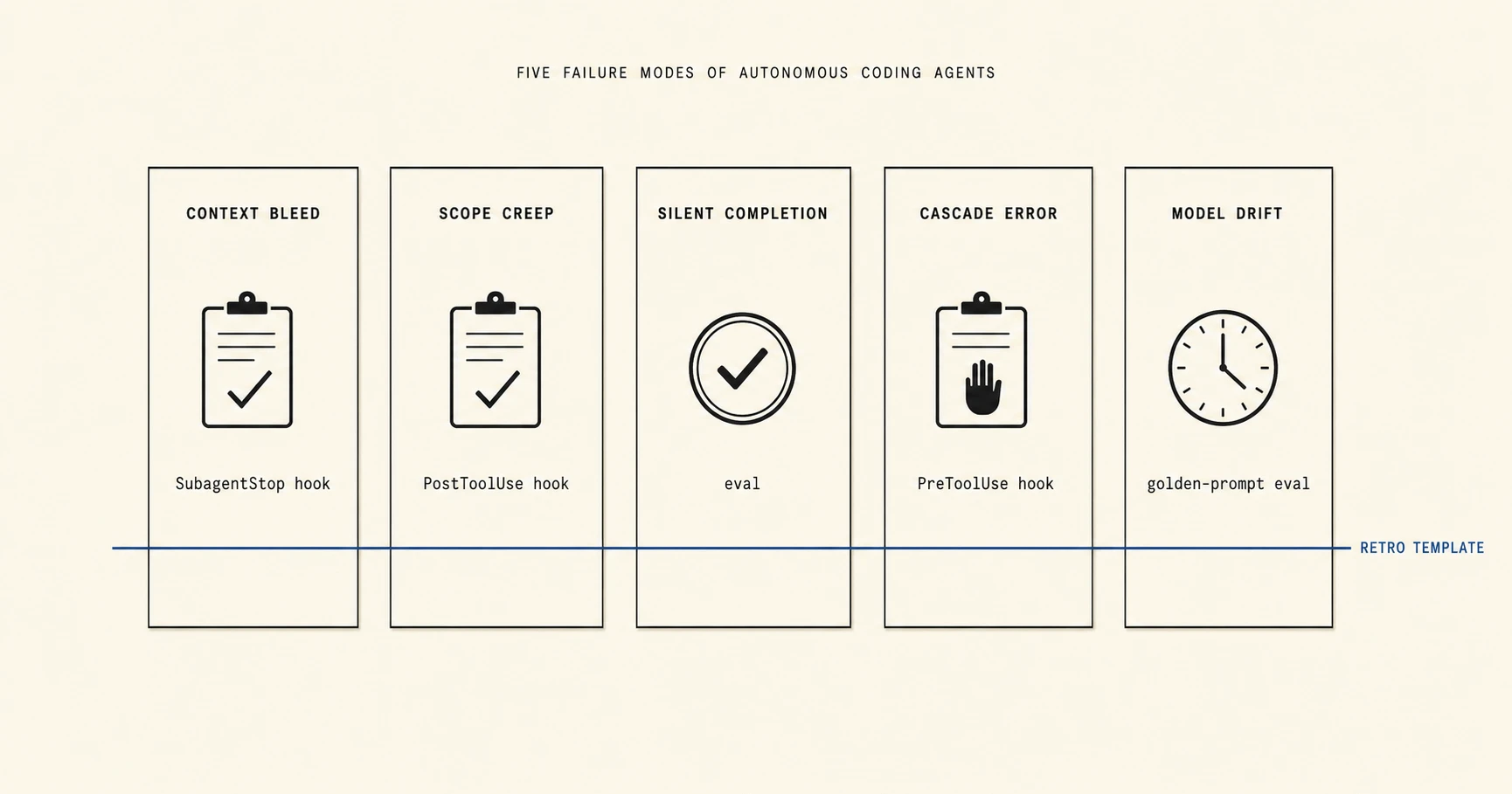
The Five Failure Modes of Autonomous Coding Agents
Five named failure modes for autonomous coding agents, each with a real 2026 incident, a detection signal, and a retro template you can drop into CLAUDE.md today.
- AI agents
- incident response
- Claude Code
- evals
- hooks

From Localhost to Production: The Handoff Brief for AI-Built Apps
45% of AI-generated code ships OWASP vulns. 380K vibe-coded apps public right now. The seven-gap handoff brief for builders and engineers.
- AI engineering
- vibe coding
- production
- security
- developer experience

UI Libraries vs AI-Generated Components: The Tailwind Substrate
Tailwind 51%, v0 4M users, shadcn passed Chakra. The library-vs-AI debate is the wrong frame: substrate placement is the right one. The four-quadrant framework.
- frontend
- AI engineering
- Tailwind
- shadcn
- developer productivity

MCP Server for Your Codebase: Tool-Shape, Not API-Mirror
Cloudflare's first MCP server would have eaten 1.17M input tokens. Their redesign got it to roughly 1,000. Here is the framework, applied to a codebase server.
- MCP
- model context protocol
- AI engineering
- developer tools
- platform engineering
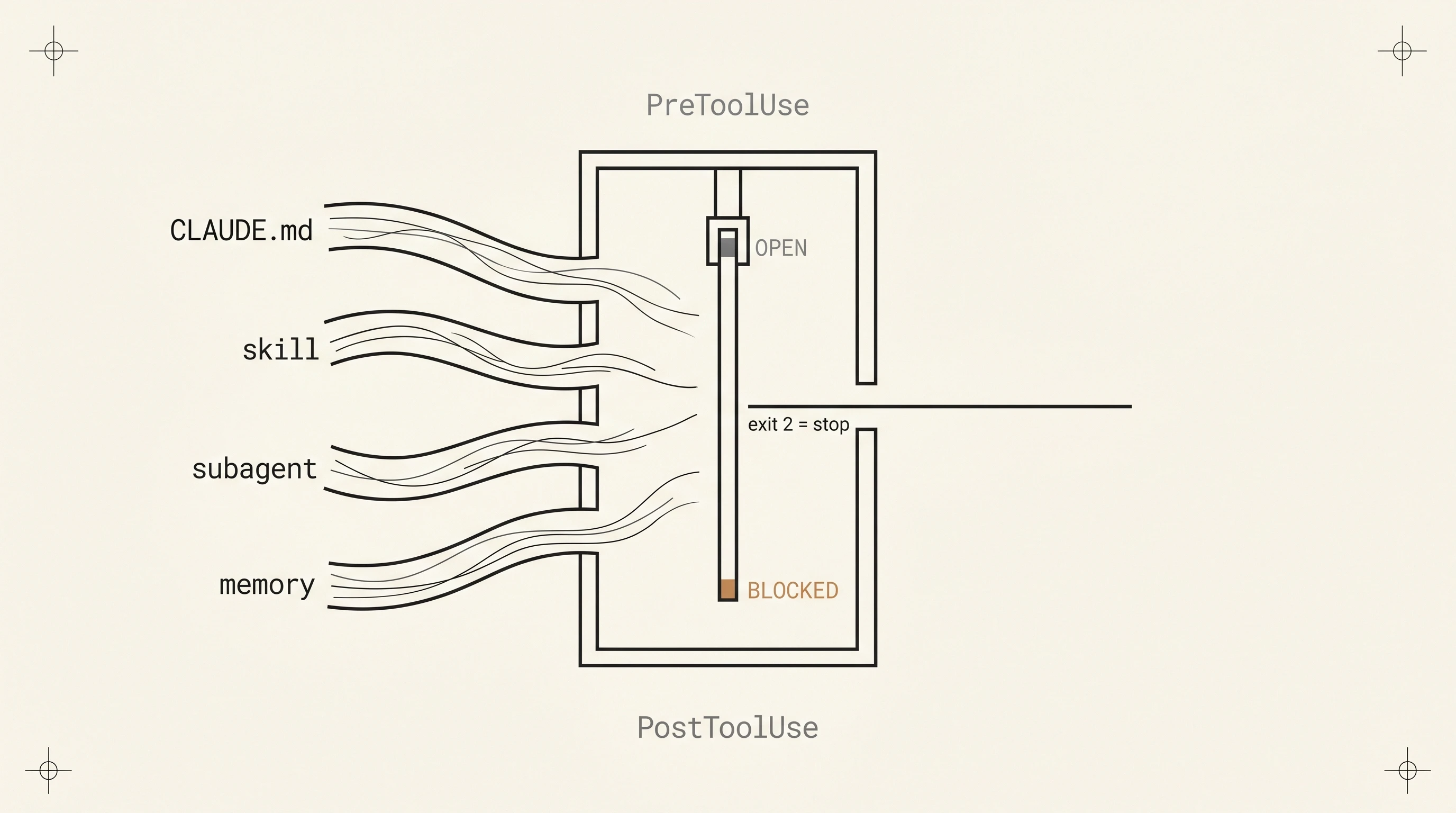
Claude Code Hooks: The Only Deterministic Substrate
The best frontier model follows under 30% of agentic instructions perfectly. Hooks run as code on every matched event regardless. Here is the substrate map.
- Claude Code
- AI agents
- hooks
- policy enforcement
- agentic coding

Agent Evals: A Test Suite for Your Claude Code Setup
Observability says what happened. Evals say if the right thing happened. 89% ship the first, 52% the second. Four control-plane evals for Claude Code.
- Claude Code
- AI agents
- evals
- agentic coding
- developer productivity
The Permission Prompt Is Dying in AI Coding Agents
Claude Code users approve 93% of prompts. For AI coding agents, prompt walls failed as governance; safety is policy: allow, gate, block, log.
- Claude Code
- AI agents
- permissions
- policy enforcement
- agentic coding
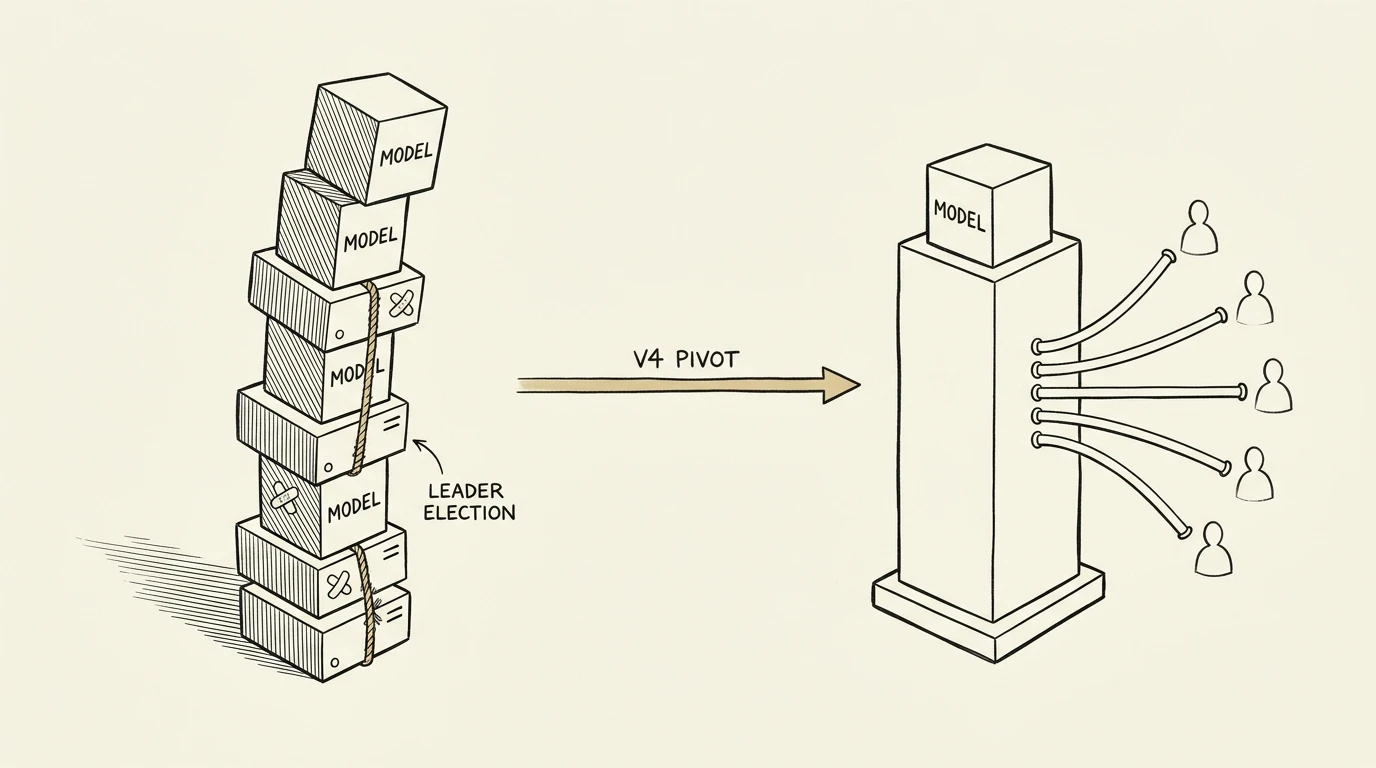
Stdio MCP Doesn't Scale: Dropping 3,662 Lines for a Daemon
Five subagents across three repos loaded 2.6 GB of duplicated embedding models. v4 deleted the stdio path; the daemon shares everything. Here is the migration.
- MCP
- model context protocol
- developer tools
- AI engineering
- platform engineering

Claude Mythos vs. the CVE Surge: AI Security in May 2026
On May 11 curl's Daniel Stenberg called Anthropic's Mythos report mostly marketing. The same six months delivered the CurXecute RCE, the Claude Code chain, and a 35-CVE March.
- AI security
- CVE
- Claude
- Copilot
- AppSec
- developer productivity

Agent Memory Architecture: Four Memories, Four Fixes
200K-context models rot by 50K tokens. Coding agents hit 150K in 35 minutes. Map four memories onto Claude Code: MEMORY.md, .remember, JSONL, skills.
- Claude Code
- AI agents
- memory architecture
- context engineering
- agentic coding
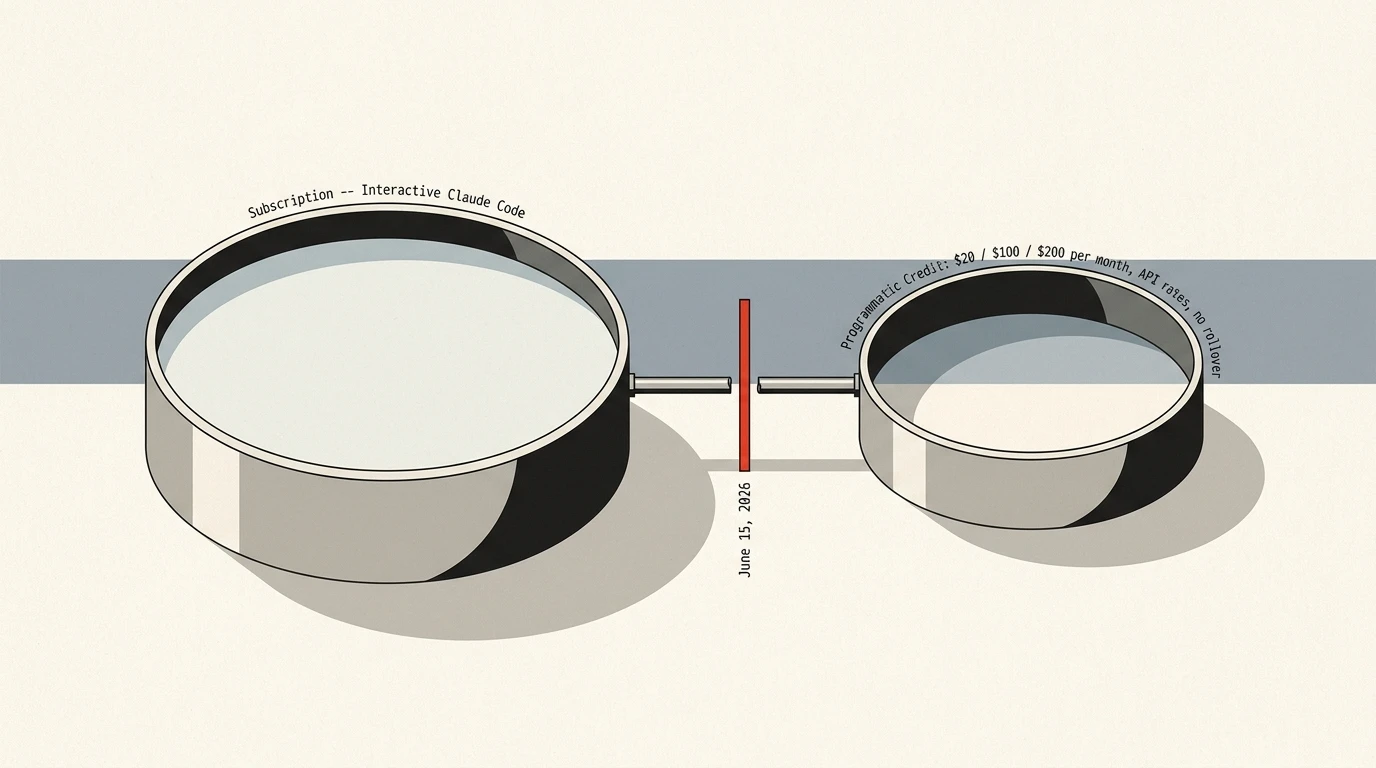
Anthropic Just Metered the Agent SDK: What Breaks on June 15
On May 13 Anthropic split Claude subscriptions into interactive and programmatic pools. Power users call it a 25x cost cut. Here is the strategic read.
- AI engineering
- Claude
- Codex
- agent SDK
- developer productivity

DORA in the Agent Era: Three Metrics Stop Measuring
DORA's four metrics measured human-paced delivery. With agents writing 46% of code and review time up 441% YoY, three no longer measure what they claim.
- DORA metrics
- AI engineering
- developer productivity
- DevEx
- engineering management

Agentic TDD: When the Failing Test Is the Spec
Spec-driven was last week's new feature. Today's spec: 17 lines of failing test. Artefact-driven TDD for follow-up agent work, against the 1.7x AI-issue rate.
- Claude Code
- AI agents
- TDD
- agentic coding
- developer productivity
Spec-Driven Agent Development: Brainstorm, Design, Plan
PR 23 told its reviewers to use MCP. They didn't. Per-agent tool calls jumped from 0.6 to 2.6 after a design doc surfaced the wiring bug prompts hid for weeks.
- Claude Code
- AI agents
- spec-driven development
- agentic coding
- developer productivity

Agent Skills: Progressive Disclosure That Actually Scales
Naive skill loading costs roughly 22x more tokens than progressive disclosure, and the attention math gets worse with every model upgrade. The pattern, the catalog math, and the authoring mistakes that break it.
- agent skills
- Claude Code
- context engineering
- progressive disclosure
- AI agents

Subagent-Driven Development: How to Fan Out a Feature Build
Subagents fan out feature builds at ~15x token cost. Wave dispatch, a frozen plan, and the five failure modes specific to subagent-driven development.
- Claude Code
- AI agents
- subagents
- developer productivity
- agentic coding

Engineering That Outlasts the Paradigm
Trust in AI accuracy hit 29% the same year vibe coding became Word of the Year. Both numbers describe the same mistake. Engineering outlasts the paradigm.
- AI agents
- software engineering
- agentic coding
- career
- thought leadership

Subagent Patterns: When to Spawn vs Stay In-Context
Multi-agent burns 15x more tokens than chat. Five-question decision tree, 2026 token math, and three reproducible failure modes for Claude Code subagents.
- Claude Code
- AI agents
- subagents
- developer productivity
- agentic coding

We Tried to Cut Claude's Output 50%. We Got 5%. So Did Anthropic.
We aimed for 50% Claude output compression. We hit 4.7%. Anthropic hit the same wall and reverted at 3%. Here is the data and the failure mode.
- claude-code
- llm-output-compression
- prompt-engineering
- claude-skills
- anthropic

Your Codebase Is the Agent's Operating Environment
Frontier agents hit 90% on SWE-Bench Verified and 21% on SWE-EVO. The variable is the shape of the codebase, not the size of the model.
- AI agents
- monorepo
- code intelligence
- code graph
- developer tooling
AI Reviews the Diff. Humans Review the Decision.
AI code-review adoption tripled to 51.4% in 2025, but 31% of PRs now merge unreviewed. Honest market scan, security posture, and a Claude Code DIY recipe.
- AI PR review
- AI code review
- Claude Code
- GitHub Actions
- developer tooling

Backtesting AI Agents: Replay to Catch Regressions
54% of enterprises ship AI agents in production. Most cannot tell when a CLAUDE.md edit silently regresses behavior. Backtesting is the missing discipline.
- agent evaluation
- backtesting
- Claude Code
- AI agents
- regression testing
- LLM as judge

Context Engineering in Practice: Where Does Each Piece Go?
Context engineering became the #1 2026 skill shift. Anthropic's research notes context exhibits n² token relationships. Here's the per-surface decision framework.
- context engineering
- Claude Code
- MCP
- AI agents
- developer productivity

Treat AI as a Team Member, Not a Chat Window
84% of developers use AI, 46% distrust it. The right scaffolding (constitution, skills, memory, MCP, subagents) turns an assistant into a team member.
- AI agents
- developer productivity
- Claude Code
- MCP
- team workflows

How to Track Claude Code 5-Hour Window Usage
40.8% of devs use Claude Code, but the 5-hour window is opaque. Build a local dashboard that parses transcripts, estimates your token budget, and rolls up team-wide cost via Grafana Loki.
- claude-code
- token-usage
- developer-tools
- ai-coding
- cost-tracking

Your AI Agent Is Flying Blind Without Local Code Intelligence
84% of developers use AI tools but 46% distrust the output. Three on-device models, 32 MCP tools, 9.93/10 relevance, and zero source code leaving your machine.
- local code intelligence
- AI agents
- MCP
- code search
- developer tools

Building an LLM Wiki: From Karpathy's Gist to a Working CLI
I turned Andrej Karpathy's LLM wiki concept into a Bun CLI (~500 lines of TypeScript) that automatically builds a persistent knowledge base from Claude Code sessions, files, and URLs.
- llm
- cli
- knowledge-management
- claude-code
- bun

How Do You Test Systems That Analyze Behavior Over Time?
Backtesting borrows from quant finance to catch temporal bugs unit tests miss. Poor US software quality costs $2.41T per year. Here's the technique.
- backtesting
- software-engineering
- data-pipelines
- temporal-data
- regression-testing
- synthetic-data
- developer-tooling