Claude Code Hooks: The Only Deterministic Substrate
Last week I added a forty-line hook to a project. The next morning my agent stopped doing the thing I had been writing into CLAUDE.md for two weeks. The CLAUDE.md paragraph was a memo. The hook was a fence. I had spent fourteen days asking the model to do something, and the fix took an afternoon and one exit 2 line. The question stopped coming back. Memos and fences are different layers, and the gap between them is wider than the docs make it look.
Engineers treat hooks as one feature among many: CLAUDE.md, skills, subagent prompts, the Memory tool, hooks. They are not. Three of those four are memos. Hooks are the only one that runs every time. This post walks the substrate distinction, proves the advisory layers fail at measurable rates, addresses the February 2026 RCE as evidence not refutation, and ends with a triage rule shaped like the substrate.
Key Takeaways
- The best frontier model follows fewer than 30% of agentic instructions perfectly across 707 real-world cases (AGENTIF, Tsinghua KEG, 2025); identical runs vary up to 15% at temperature 0 (Stability Trap, arXiv 2601.11783, 2026).
- Claude Code v2.1.89+ exposes 31 lifecycle hook events across nine categories; four carry most of the weight (
PreToolUse,PostToolUse,SessionStart,Stop) (Anthropic Hooks reference, 2026).- The February 2026 RCE (CVE-2025-59536, CVSS 8.7) is evidence of substrate, not its refutation; CLAUDE.md has never had a CVE because nothing depends on it (Check Point Research, 2026).
- Memos and hooks are complements; only one is unconditional. If a behaviour is load-bearing, it lives in a hook.
What runs every time?
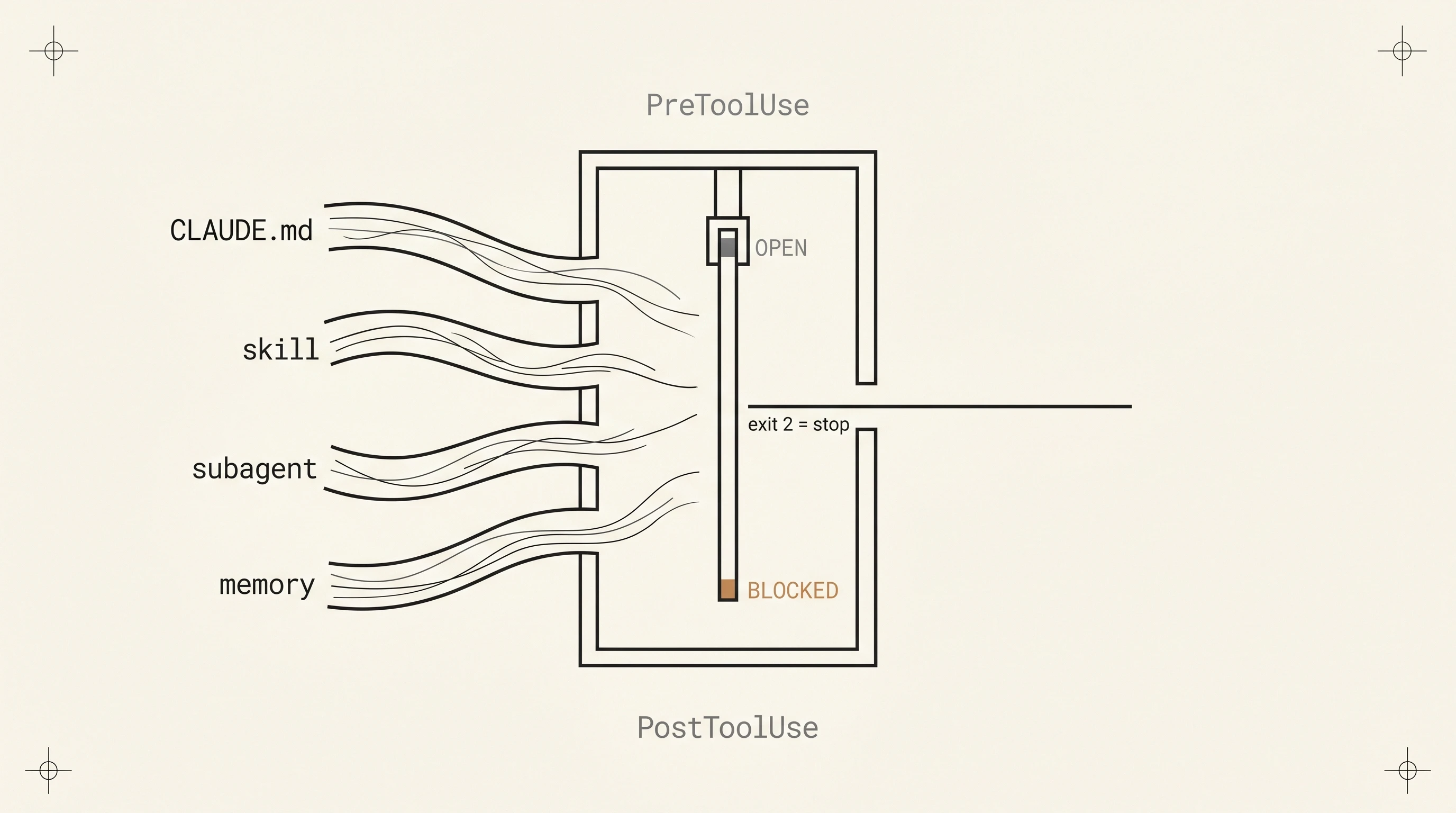
Of Claude Code’s five behaviour-shaping primitives (CLAUDE.md, skills, subagent prompts, the Memory tool, and hooks), only hooks execute as code at the system level on every matched event (Anthropic Hooks reference, 2026). The other four are inputs to the model’s reasoning chain. Hooks are not.
CLAUDE.md is a markdown file. The session prepends it to the prompt, the model reads it, and from there the model decides what to do with it. A skill is the same shape with a trigger word: progressively disclosed prose the model retrieves when it judges the skill relevant (related: skills are progressively-disclosed memos). A subagent prompt is a memo passed to a different session. The Memory tool is a place to put bytes the model can fetch when it remembers to. All four are inputs the model considers.
A hook is none of those. A hook is a shell command (or any executable) Claude Code runs on a lifecycle event whether the model agreed, remembered, or noticed. The model does not choose to run a hook. The system runs it.
The exit code controls the loop: exit 2 blocks the event, anything else allows it. Anthropic’s own guidance is direct: “If your hook is meant to enforce a policy, use exit 2.”
The distinction is not “feature versus convention.” It is “considers versus does.” A memo gets read; a fence gets enforced. The compliance gap between the two is wide enough that it is the topic of the next section.
The chart below sketches the gap. Three advisory bars cluster around 30% perfect compliance with a Stability Trap variance band; one substrate bar sits at 100% by definition. Same prose at four layers, four different success rates.
How often do the advisory layers actually fail?
The empirical compliance gap between memo and code is roughly 70 percentage points. The best frontier model follows fewer than 30% of agentic instructions perfectly across 707 real-world cases (AGENTIF, Tsinghua KEG, 2025). Identical runs at temperature 0 vary up to 15% in instruction adherence (Stability Trap, arXiv 2601.11783, 2026). Policy adherence pass rates land between 31% and 69% across multi-step single-turn agentic tasks (arXiv 2507.16459, Jul 2025).
AGENTIF is the most embarrassing of the three. The benchmark covered 707 instructions drawn from 50 real-world agentic applications, each averaging roughly 1,700 tokens and fourteen constraints. The best frontier model could not perfectly satisfy a third of them. Not “incorrect on subtle edge cases”; perfectly missing one or more named constraints in the prompt. That is the ceiling on “asking the model nicely.”
The Stability Trap is the second sting. Identical inputs, identical model, temperature 0: the same prompt produces outputs whose instruction-adherence varies by up to 15% across runs. There is no setting at which advisory layers become reproducible. The variance is structural to the sampler. You cannot tune it away.
The 31% to 69% policy adherence range from arXiv 2507.16459 covers multi-step single-turn agentic tasks across five domains. GPT-4.1 reached 0.82 with manual ground-truth and 0.75 automatic; smaller models landed lower. The headline is the spread, not the peak. A 38-point gap between the ceiling and the floor is not a tuning problem. It is a substrate property.
Three studies, three angles, one conclusion: advisory layers fail at measurable, consistent, irreducible rates. This is not a “models will get better” problem. The compliance ceiling is the ceiling. A behaviour whose first failure is unrecoverable cannot be expressed as instructions to the model and expected to hold.
The thirty-one events you can actually attach to
Claude Code v2.1.89+ exposes 31 hook lifecycle events across nine categories: session, per-turn, agentic loop, turn-completion, team, file/config, context/compaction, worktree, and MCP (Anthropic Hooks reference, 2026). Crosley reports 95 hooks running across 6 of those events with roughly 200 ms total overhead per event (Blake Crosley, Apr 2026).
The count keeps climbing. Earlier guides quote twelve events; the editorial calendar entry I wrote for this post in early May 2026 said “26 events”; current docs list thirty-one. The growth is not the headline. The headline is that four of the thirty-one carry most of the weight.
PreToolUse is the only place to deterministically prevent. The hook fires before the model’s tool call executes, and a process exit of 2 blocks the call entirely. The model receives a structured rejection it cannot rationalise away. This is where “never run rm -rf in this repo” stops being a memo.
PostToolUse is the only place to deterministically react. Audit, redact, rotate, count tokens, parse the tool’s output. The hook runs every time the matched tool returns, not when the model decides logging is interesting.
SessionStart is the only place to inject context the model cannot forget to read. Whatever the hook prints to stdout enters the session prompt. The “remember to check .remember/now.md” line in CLAUDE.md becomes a hook that reads it for you.
Stop and SubagentStop are the only places to consolidate state before the loop exits. Rotate today’s working buffer, archive at week boundaries, summarise the JSONL transcript. Memory persists by code, not by reminder.
Lightweight matchers are essentially free: single-digit milliseconds for grep, jq, or a file-path check. Pairing slow operations like tsc --noEmit with high-frequency events causes ~20-second CLI freezes (ruvnet/ruflo issue #1530). Match precisely; the overhead budget rewards it.
Where is the leverage highest?
The four highest-impact hook events compress what would otherwise be advisory paragraphs into deterministic guarantees. A PreToolUse exit-2 against rm -rf is worth more than any number of CLAUDE.md warnings; a Stop hook that rotates a daily memory file is worth more than asking the model to remember to do so.
Pre-tool grep filter. A PreToolUse hook on Bash matchers can intercept long log reads, run grep against the requested file, and return the filtered output. The model sees hundreds of tokens instead of ten thousand. The hook does the work; the model never knew there was anything to skip. Same effect as “always grep before reading large logs” in CLAUDE.md, except it actually happens. Use this to track token usage deterministically.
PreToolUse policy hook. The fence equivalent of “never run dangerous commands.” A short shell script greps the planned tool input for a deny-list, prints a structured rejection to stderr, and exits 2. The block is unconditional. The model can rationalise around prose; it cannot rationalise around an exit code.
SessionStart context injection. The cleanest replacement for the CLAUDE.md paragraph the model keeps ignoring. A hook reads .remember/now.md (or any other state file) at session start and prints its contents. The “remember to check” instruction never fires because there is nothing left to remember; the substrate placed the bytes in the prompt. This is the deterministic version of context engineering at temperature 0.
Stop / SubagentStop consolidation. A hook on session end writes the working buffer to a dated file, archives last week’s, and rotates the buffer to empty. The model does not have to choose to consolidate. Memory persists because the code does.
The repeated move is the same in all four. Replace “CLAUDE.md says …” with “the system enforces …”. Same behaviour, different layer, different success rate. The compliance ceiling on the first form is around 30%. The ceiling on the second form is whatever the shell command’s correctness rate is, which for a deny-list grep is essentially 100%. Skills cover guidance with optionality; hooks cover behaviour without it.
But the February 2026 RCE: doesn’t that change everything?
It does not. Check Point disclosed CVE-2025-59536 (CVSS 8.7) and CVE-2026-21852 (CVSS 5.3) in February 2026, demonstrating that a malicious .claude/settings.json could execute shell commands at SessionStart (Check Point Research, 2026; The Hacker News, Feb 2026). Anthropic patched the vulnerability between August 26 and August 29, 2025, before public disclosure. Hooks remain the only deterministic substrate. The CVE is evidence of substrate, not its refutation. CLAUDE.md has never had a CVE because nothing depends on it.
The disclosure timeline matters. Check Point reported on July 21, 2025; Anthropic patched on August 26; the GHSA published on August 29; public disclosure landed on February 25, 2026. The vulnerability had a fix on the shelf for six months before the press cycle. The vendor response is not the load-bearing part of the story. The shape of the vulnerability is.
The default narrative reads the CVE as a hooks problem. Several existing posts on the subject update with a defensive footnote conceding the framing. They have it backwards. Untrusted-repo .claude/settings.json execution belongs to the same class as untrusted-repo .git/hooks/post-checkout. The fix is a trust boundary, not a substrate change. Anthropic’s current guidance is to audit hook configurations the way you audit .envrc or shell-rc imports. Treat config-as-code from a clone as code from a clone.
That concession aside, the inversion holds. A vulnerability of this class can only exist in a layer that runs untrusted code at the system level on a deterministic event. CLAUDE.md cannot have a CVE because no command runs from CLAUDE.md. Skills cannot have a CVE because no command runs from skills. The Memory tool is bytes-at-rest.
The exploitable layer is the one with teeth. The teeth are also the leverage. The CVE is the proof, not the disqualification.
Hooks and skills, hooks and CLAUDE.md, hooks and subagents
Skills, CLAUDE.md, and subagent prompts solve a different problem than hooks. They shape what the model considers; hooks shape what the system does. The two layers are complements, not alternatives, but only one of them is unconditional (Anthropic Hooks reference, 2026).
Hooks vs CLAUDE.md. CLAUDE.md is the right layer for house style, project context, and rules whose costs of imperfect compliance are low. “Prefer Bun over Node” is a memo and stays one. Hooks are the right layer for anything whose cost of one failure exceeds the cost of one false positive. Use both. Stop using CLAUDE.md for the second class.
Hooks vs skills. Skills are progressively-disclosed memos. They run when the model decides they are relevant; the trigger is the model’s judgement, which we just established is bounded around 30% on AGENTIF. Hooks run on a lifecycle event whether the model agrees or not. Use skills for guidance with optionality; use hooks for behaviour without it.
Hooks vs subagents. Subagent prompts are memos passed to a stranger. The stranger’s compliance distribution is identical to the parent’s: under 30% on AGENTIF, with a 15% temperature-0 variance. A SubagentStop hook that validates the subagent’s output is the only deterministic check on what the stranger actually returned.
Hooks vs the Anthropic Memory tool. The Memory tool is a place to put bytes the model can fetch. A hook decides when those bytes get rotated, hashed, redacted, or written. The tool is storage; the hook is the policy. They live on different layers; conflating them is the same conflation as treating CLAUDE.md as a fence (related: the four-memory map).
Comparable systems lack this layer. Cursor’s .cursor/rules is natural-language and advisory. Cline’s .clinerules/ is markdown and advisory. Aider has no lifecycle hooks at all. None offer deterministic shell-exec at lifecycle events. Claude Code’s hooks are not just a feature; in the current category, they are the substrate. Treat the agent as a team member only works if the team member runs on something.
What does a substrate-shaped policy look like?
Adopt one rule: if a behaviour is load-bearing, it lives in a hook; otherwise it lives in a skill or in CLAUDE.md. The boundary is not feature-by-feature; it is failure-cost. Anything whose first failure is unrecoverable belongs to the substrate.
Triage:
- Cost of one failure unrecoverable (data loss, credential leak, accidental commit to main, dangerous shell command): hook with
exit 2. The compliance number you need is 100%. Memos cannot deliver that. - Cost of one failure annoying (re-explaining a constraint, missing a style rule, a forgotten convention): skill or CLAUDE.md. The compliance number you need is “most of the time, eventually.” Memos can deliver that.
- Cost of one failure invisible (telemetry, audit log, daily rotation, token counting): non-blocking
PostToolUseorStophook. The compliance number you need is 100%, but blocking is unnecessary. Run the work; do not interrupt the loop.
Walk a single behaviour through the three layers. “Never commit secrets.” As a CLAUDE.md paragraph: ~30% perfect compliance, with a 15% variance band. As a skill: same ceiling, with the model judging the trigger. As a PreToolUse hook on Bash git commit matchers grepping for AKIA, -----BEGIN, and the project’s known secret patterns: 100% compliance with a small false-positive rate. The behaviour is identical at all three layers; the success rate is not.
The hook I wish I had written six months earlier was a Stop hook on this site’s repo that rotates .remember/now.md into today-DATE.md at session end. CLAUDE.md asked the model to do it. The model did, sometimes. The hook does it every time. The buffer never bleeds into the next session, the daily log never has gaps, and I stopped re-asking the question.
Frequently Asked Questions
What is a Claude Code hook?
A hook is a shell command (or any executable) Claude Code runs on a lifecycle event such as PreToolUse, PostToolUse, or Stop. The command’s exit code determines whether the event proceeds: exit 2 blocks, exit 0 allows. Configured in .claude/settings.json or ~/.claude/settings.json (Anthropic Hooks reference, 2026). Unlike CLAUDE.md or skills, the system runs hooks regardless of the model’s decisions.
How many Claude Code hook events are there?
Claude Code v2.1.89+ exposes 31 lifecycle events across nine categories: session, per-turn, agentic loop, turn-completion, team, file/config, context/compaction, worktree, and MCP (Anthropic Hooks reference, 2026). Older guides quoting twelve or twenty-six events are stale; the count has grown over the last two releases. Four events (PreToolUse, PostToolUse, SessionStart, Stop) carry most of the weight in practice.
Are Claude Code hooks safe after CVE-2025-59536?
The vulnerability is patched. Anthropic patched between August 26 and 29, 2025; public disclosure was February 25, 2026 (Check Point Research, 2026). The remaining advice matches any project-level config-as-code: audit .claude/settings.json from untrusted repositories the way you would audit .envrc or .git/hooks/post-checkout. Hooks remain the only deterministic substrate.
What is the difference between a hook and a skill?
A skill is a progressively-disclosed memo the model reads when it decides the skill is relevant. A hook is a shell command the system runs on a matched event regardless of model decisions. Skills shape what the model considers; hooks shape what the system does. The empirical compliance gap is roughly 70 percentage points (related: agent-skills-progressive-disclosure).
Memo or fence?
The compression of the entire argument lands on those two words. CLAUDE.md, skills, subagent prompts, and the Memory tool are inputs the model considers; hooks are code the system runs whether the model considered or not. If a behaviour matters, it cannot live in memory. It must live in a hook.
- 31 lifecycle events; four (
PreToolUse,PostToolUse,SessionStart,Stop) carry most of the weight. - Advisory compliance ceiling around 30%; hook compliance is whatever the shell command’s correctness rate is.
- The February 2026 CVE is evidence of substrate, not its refutation.
- Memos and hooks are complements; only one is unconditional.
Audit your last week of CLAUDE.md edits. For each rule, ask one question: memo or fence? Move the load-bearing ones to hooks before the next session starts.
If it was useful, pass it along.