The Project Graph: What Agents Need That Filesystems Can't Give
Your agent runs grep, cat, grep for ten turns to answer one question about a function’s callers. The filesystem gave it strings. The work needed a graph. On a small repo, that round-trip is invisible: a few thousand tokens, two seconds, done. On any real codebase, the same loop costs tens of thousands of input tokens per turn, eats the cache, drifts off-topic, and still gets the answer wrong half the time because string matches on a name like processOrder overlap with comments, test fixtures, SQL columns, and three sibling variables.
This post is about the abstraction sitting underneath that failure. Every coding agent. Claude Code, Cursor, Aider, Codex. Ships with filesystem-shaped tools by default: read_file, list_directory, grep. Those are fine for path I/O. They are the wrong substrate for semantic questions, because a filesystem is a tree of strings and coding work is a graph of edges (calls, references, types, ownership, recency). Until something hands the agent the graph, every turn reconstructs it by hand at O(file-size) token cost.
A primitive is missing. It is being half-built in product launches (GitNexus in April, CodeGraph in May, Sourcegraph Cody, the code-intelligence MCP I have been writing about), and the underlying argument for why the filesystem is wrong rather than just incomplete keeps getting skipped. Name it: project graph. Distinguish it from LSP, from code search, from knowledge graphs. Then put the second-order claim under measurement: does giving the agent a graph-shaped surface actually reduce the cost of semantic questions, or just add tools the agent uses for triangulation while still falling back to grep?
I built a proper benchmark to measure this. Forty questions, twenty against a private notarisation repo of mine (a Tauri desktop + cloud app: Rust on the native and indexer side, TypeScript on an Elysia backend, React/TSX on the renderer, roughly 217K lines of source code total: Rust ~97K, TypeScript ~71K, TSX ~43K, plus HCL, SQL, shell, and CSS) and twenty against Django 5.1.4 (Python, mature framework, ~400K LOC), pinned to a fixed SHA so the citations the agent emits can be verified against the actual codebase. Five toolset arms, three of which matter for “should I use this”: default (Claude Code with Read/Grep/Glob/Bash only), code-intelligence (my MCP daemon v4.1.2, the lean shipped config), and CodeGraph (colbymchenry’s competitor MCP). Same Claude Code agent, same questions, same model on every arm. Only the tool surface differs. Questions span six task types: symbol lookup, architecture, concept, impact analysis, multi-hop tracing, and negative cases (“what doesn’t exist in this codebase?”).
Each answer gets two independent scores. Mech (0.0-1.0) is mechanical accuracy: 0.5 × citation_hit + 0.25 × file_score + 0.25 × fact_score, multiplied by a citation-verification factor (1.0 if every cited file:line actually exists at the pinned SHA, 0.5 if any cite is hallucinated, 0.0 if all are), minus 0.25 per forbidden-pattern hit. Judge (0-10) is the median of three independent LLM judges (Haiku 4.5, Sonnet 4.6, Opus 4.7) grading synthesis quality on the same answer. Two scores per question across 40 questions × 3 toolsets = 120 mech datapoints and 360 judge ratings per round.
Key Takeaways
- Filesystems give agents a tree of strings (path, content, mtime). Coding work is a graph of edges (calls, references, types, ownership). The abstraction argument is right at the theoretical level: filesystem cost scales with codebase size; graph cost scales with answer size.
- Code-intelligence vs default Claude Code (R005, n=40): judge 7.12 vs 6.30 (+0.82), wall 37.3s vs 52.4s (29 percent faster), tokens 177K vs 164K (+8 percent). The default agent scored a clean 0 on four questions it couldn’t handle at all (one architecture, one concept, two cross-cutting); code-intelligence never bottomed out. The graph’s value is the floor it puts under hard questions, not edging out grep on easy ones.
- Code-intelligence vs CodeGraph (R005, n=40): tied on judge (7.12 vs 7.15, well inside the ±2 judge-disagreement band) but code-intelligence is materially more citation-accurate (mech 0.426 vs 0.331, citation-hit 50 percent vs 32 percent) while using 19 percent fewer tokens (177K vs 219K) and fewer tool calls (5.1 vs 7.0). CodeGraph writes prose the judges like but cites less reliably. Two of CodeGraph’s questions earned a clean 0 from citation-verification failure: it cited
file:linelocations that don’t exist at the pinned SHA.
What does the filesystem actually give the agent?
A filesystem hands the agent five things and stops there: path, content, mtime, size, and parent/child structure. That is the entire schema. Turso’s analysis of agent runtimes named this gap in early 2026 — filesystems were designed for humans browsing folders, not agents reasoning about code (Turso AgentFS, 2026). Every semantic question, every “who calls X?”, “what implements Y?”, “what changed near Z?”, gets answered by composing those five primitives through reasoning. The agent runs grep, reads the matches, reasons about which ones are the real referents, and pays the full token cost of every file it touches.
Cost shape: O(file-size). To answer one callers question, the agent issues grep -r processOrder src/, receives 47 hits across 23 files, and then has to disambiguate. Is each hit the function, a method on a different class with the same name, a comment, a test name, or a SQL column reference in a string literal? The only way to know is to cat the surrounding context. Five reads later the agent has ~15K input tokens of mostly-irrelevant code in its context window and still has to reason through what was actually returned.
The Feb 2026 arxiv paper “Everything is Context: Agentic File System Abstraction” formalised this gap empirically, arguing that file-shaped tool surfaces force agents into a navigation paradox: as the codebase grows, the cost of finding the relevant pieces grows faster than the codebase itself, because disambiguation rounds compound multiplicatively (arxiv 2512.05470). This is not a Claude Code problem or a Cursor problem. It is an abstraction problem; every IDE-style filesystem tool shape inherits it.
The reasoning runs out of patience before the codebase runs out of grep matches. The agent commits to an answer with partial coverage, and the failure mode is not loud. It is silent: a confidently wrong “no callers found except these three” when there were nine. The filesystem gave the agent the strings it asked for; the agent had no way to ask the question the work needed.
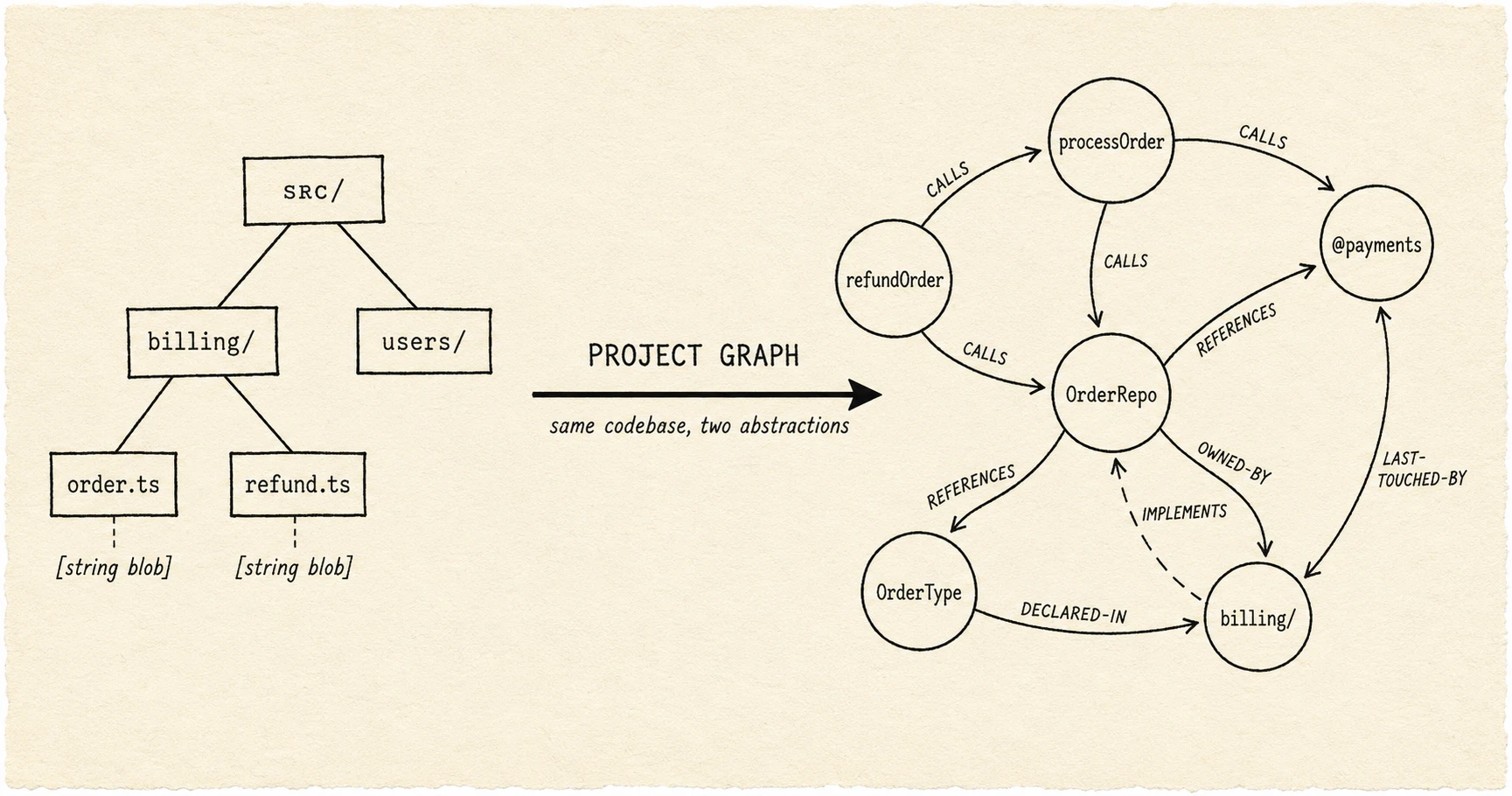
What is a project graph?
A project graph is a maintained index of a single codebase, expressed as nodes (symbols, files, modules, types, owners, commits, tests) and edges between them (calls, references, implements, declared-in, last-touched-by, owns, tests). One query against the graph answers the kind of question grep-and-read takes ten turns to approximate. The shape mirrors the semantic-memory layer covered in agent memory architecture; the difference is that the codebase already is the data, not a summary of it. It is not a knowledge graph (too generic), not a call graph (too narrow), not code search (different layer). It is the abstraction shaped to the work coding agents actually do.
A minimal schema sketch:
- Nodes:
Symbol(name, kind, file, line, signature),Module(path),Type(name, declared-in),Owner(team, person),Commit(sha, ts),Test(name, covers). - Edges:
Symbol -calls-> Symbol,Symbol -references-> Symbol,Symbol -declared-in-> Module,Symbol -implements-> Type,Module -owned-by-> Owner,Symbol -last-touched-by-> Commit,Test -covers-> Symbol.
Query shapes the graph answers in one call:
- Who calls X? Traverse
-calls->inbound from the symbol node. Returns enclosing symbol, file, line, and signature. - What implements Y? Traverse
-implements->inbound from the type node. - What changed near Z this week? Filter
-last-touched-by->by commit timestamp, then expand outward to neighbouring symbols. - What tests cover W? Traverse
-covers->inbound from the symbol. - Who owns module M? Single edge from the module node to its owner.
None of these reduce to a substring search. Each is a structural property of the codebase that exists whether or not the agent ever asks for it; the question is whether the agent has any way to ask.
The naming matters because every adjacent term has been claimed without the abstraction being defined. “Code intelligence” is vendor branding (Sourcegraph, Aider, Cody). “Code graph” usually means call graph specifically. “Knowledge graph” is the document layer. “Project graph” is the term that fits the data, and using it consistently across the rest of the post is a deliberate choice. The primitive is real; it just has not been named in a way that survives marketing.
How does the graph-shaped surface actually compare?
The argument so far is theoretical: filesystem is wrong-shape; graph is right-shape; therefore graph should be cheaper or better (or both) for semantic questions. Whether that translates into observable wins is a separate question from whether the abstraction is right, and it has to be measured against more than one repository and more than one judge.
The numbers below come from R005 (2026-05-28), the first cross-repo bench cycle. Each arm is the same Claude Code agent answering the same 40 questions, differing only in which MCP tools it has plus one paragraph of tool guidance. Full raw data and the harness sit in the code-intelligence repo’s bench/ directory and are reproducible from a clean checkout against the Django fixture; the notarisation-repo fixture is private but uses the same harness, fixture format, and scoring path as the Django one.
The headline three-arm comparison:
| toolset | tool surface | judge (clean) | mech | citation accuracy | tokens | tool calls | wall |
|---|---|---|---|---|---|---|---|
| default | Read / Grep / Glob / Bash only | 6.30 | 0.409 | 52% | 164K | 5.2 | 52.4s |
| code-intelligence (shipped lean config) | + 11 MCP tools | 7.12 | 0.426 | 50% | 177K | 5.1 | 37.3s |
| CodeGraph | + 7 codegraph tools | 7.15 | 0.331 | 32% | 219K | 7.0 | 46.9s |
Two readings sit on top of that table.
Versus a plain grep/read agent, code-intelligence wins on judge (+0.82) and wall time (29 percent faster) for an 8 percent token premium. The judge mean gap (7.12 vs 6.30) understates the per-question picture. The head-to-head is 17 questions where code-intelligence beats default, 14 where default beats code-intelligence, and 9 ties. Default doesn’t lose because it loses small; it loses because it fails catastrophically on a handful. Four questions earned a clean 0 from the default agent: django-arch-03, django-concept-01, django-multi-hop-04, django-negative-02. All four are tasks where grep finds nothing useful (architecture summaries, concept queries, identifying things that don’t exist). Code-intelligence never bottomed out. The graph’s value is the floor it puts under hard questions, not edging out grep on the easy ones.
Versus CodeGraph, the judges call it a tie (7.12 vs 7.15, well inside the ±2 inter-judge disagreement band). But code-intelligence is materially more citation-accurate: mechanical score 0.426 vs 0.331, citation-hit 50 percent vs 32 percent, while spending 19 percent fewer tokens (177K vs 219K) and 27 percent fewer tool calls (5.1 vs 7.0). CodeGraph writes prose the judges like. Two of CodeGraph’s answers (django-symbol-01, django-concept-03) earned a clean 0 from the verification factor: they cited file:line locations that don’t exist at the pinned SHA. That is the kind of confident-but-wrong answer that becomes very expensive once an agent starts acting on it without a human in the loop.
The per-task-type breakdown is where the abstraction argument shows up most clearly.
Both graph products beat default on 5 of 6 task types. The exception is impact analysis (filesystem 7.3 vs code-intelligence 6.5 vs CodeGraph 7.0). Impact tasks are “if I change X, what downstream code is affected?”, and the failure is that current graph responses give the agent enough surface to reason about, but not the call-graph closure needed to enumerate full downstream impact; the agent then short-circuits where a grep agent kept widening. That is a real result of the bench and a real product gap on the graph side. The other five task types show the pattern the abstraction argument predicts: graph wins biggest on negative (+2.2 over default), architecture (+1.3), concept (+1.0), symbol lookup (+1.0), and multi-hop (+0.6).
The per-repo split is interesting and worth being careful about. On the notarisation repo (polyglot Tauri app, ~217K LOC), code-intelligence beats default by +0.45 on judge (6.90 vs 6.45). On Django 5.1.4 (single-language Python framework, ~400K LOC), code-intelligence beats default by +1.20 (7.35 vs 6.15). Both are large codebases, so this is not a simple “LOC scaling” story. The most plausible read is codebase maturity: Django has decades of stable internal APIs with deep fan-in (many callers per symbol), which is exactly the shape graph navigation pays off on, where grep’s disambiguation cost compounds. The notarisation repo is newer, has fewer internal callers per symbol, and grep gets away with more. CodeGraph’s per-repo behaviour bears this out: its citation accuracy holds on the notarisation repo (45 percent hit) and collapses on Django (20 percent hit, mech 0.28), where the same file:line pattern can plausibly appear in dozens of places. The honest caveat: n=20 per repo and question authoring varies across the two fixtures, so this could also be partly question-difficulty variance, not pure repo-property variance.
The honest scope: n=40 across two repos, single round, judge disagreement runs ±2 points so sub-±0.5 differences between arms are inside the noise. The 7.12-vs-7.15 tie between code-intelligence and CodeGraph is genuinely a tie. The +0.82 gap over default is well outside the noise band. The reproduction commands are in the bench README; nothing here requires trusting my arithmetic over the raw runs.jsonl and judge.jsonl in the repo.
Why doesn’t LSP just solve this?
LSP. The Language Server Protocol. Already implements a project graph: textDocument/references, textDocument/definition, textDocument/callHierarchy/incomingCalls. The primitive is there; every major language has at least one server; the spec has been published and refined since 2016 (Microsoft LSP, 2016-2026). So why do coding agents not just use LSP and call the problem solved?
Because LSP is the IDE-shaped version of the primitive, and an agent is not an IDE.
Four mismatches matter:
- Cursor-position queries vs symbol-space queries. LSP requests need a file URI plus a line and column. Agents work in symbol space (“the
processOrderfunction insrc/billing/”), not cursor space. Every query the agent issues has to be mapped through a position resolution step the agent pays for in reasoning tokens. - Single-call responses vs batched, filtered responses. LSP returns one set of references per request. Agents need “give me callers for these eight symbols, filtered to
src/billing/, ranked by who touched them in the last sprint” in one call. LSP servers do none of that. - Per-file-open memory model vs whole-codebase queries. LSP servers are tuned for IDE memory pressure: one or two files open, fast incremental updates, expensive cold start. Agents need cross-codebase answers, often across multiple language servers (the typescript LSP does not know about the Python LSP’s symbols), and they do not benefit from the per-file caching IDEs were designed around.
- Positional responses vs semantic responses. LSP returns ranges. Agents need enclosing symbol, signature, summary, ownership; they are reasoning about what the code does, not where the cursor goes.
LSP is a usable substrate underneath, not a usable surface above. The job of an agent-facing tool layer is to wrap an LSP-grade index (or build one) and expose verbs the agent can compose. That is why MCP servers like code-intelligence exist; they are not “LSP for AI.” They are an agent-shaped surface over the same primitive, often with LSP as one of the inputs.
Where should the project graph actually live?
The abstraction decision (project graph vs filesystem) is independent of the substrate decision (where the index runs). Anthropic’s MCP code-execution write-up walks through running the same agent tool surface across multiple transports (Anthropic Engineering, 2026); the same project graph fits any of them. Four substrates exist for serving the graph to an agent, and each has a different operational profile.
- In-process / embedded. The agent runtime loads the index. Works for small repos, hot reload painful, no sharing across agents. Fine for a personal Aider session on a side project; collapses under multi-agent workflows.
- Language server (LSP). Mature, well-tested, IDE-shaped surface. Wrong fit for batched and semantic queries, as covered above. Useful as an input to a higher-level tool layer; not the layer itself.
- MCP server, stdio. The popular default. One subprocess per client, dies with the chat session. Pays subprocess plus index-load cost on every cold start. Documented elsewhere why this collapses under multi-agent fan-out: every spawned subagent gets its own subprocess, every chat session restarts from cold.
- MCP server, HTTP daemon. One index, many agents on the same machine, leader election unnecessary, lifecycle outlives any single chat session. Where code-intelligence v4 landed after the stdio rewrite.
The choice between the four is operational, not conceptual. The same project graph fits any of them. What matters is that the substrate amortises the cost of building and maintaining the index across queries; otherwise the graph’s amortised-O(answer-size) advantage gets swamped by paying O(codebase-size) for index construction on every turn.
Index build cost is paid once per edit batch, not per turn. For a 200K LOC repository, building the graph from scratch takes seconds on a modern laptop and an incremental rebuild after a normal edit takes milliseconds. Query cost is paid per turn. Filesystem shape pays query cost on every turn forever; graph shape amortises across a session and across sessions if the substrate persists. That is the whole game.
When is the filesystem still the right answer?
The point of naming the project graph is not to retire the filesystem; it is to stop pretending that filesystem tools answer semantic questions cheaply, and to stop pretending that adding graph tools automatically makes them cheap. On a Django-sized codebase (~400K LOC) the cold index completes in seconds for CodeGraph (tree-sitter only) and roughly a minute for code-intelligence; both stay in incremental-rebuild mode in the background after that. Below roughly 5K LOC the build cost exceeds the navigation savings and the filesystem still wins outright. There are real situations where the graph is over-engineering and the filesystem is the right choice. The bench also showed one task type where the filesystem actively beats both graph products (impact analysis: default 7.3 vs code-intelligence 6.5 vs CodeGraph 7.0). Pick by question shape, not by tool habit. And pick by measured cost on your own questions, not by category narrative.
Use the filesystem when the repository is under roughly 5K LOC (graph payoff is smaller than build cost), when the questions are path-shaped rather than semantic (“what is in this folder?”, “read config.json”), when the agent only edits without navigating (“rename this variable across these three files”), or when the agent is supervised and the filesystem’s cost is your time rather than the agent’s tokens.
Use a project graph when the repository is over roughly 20K LOC and growing, when the agent does cross-file reasoning (“find every caller of processOrder that bypasses validation”), when sessions run long enough that filesystem cost compounds, or when multiple agents fan out and each would otherwise pay its own filesystem-reconstruction cost.
Use a hybrid, which is what most teams should actually do: a graph-shaped tool surface for navigation queries, filesystem tools for I/O and config. The graph does not replace the filesystem; it sits beside it and answers the semantic questions the filesystem cannot. The agent then picks by question shape, which is exactly the routing decision the 11-tool code-intelligence surface is designed to make easy.
FAQ
What is a project graph?
A project graph is a maintained index of symbols, files, types, owners, and the edges between them (calls, references, implements, declared-in, last-touched-by). It is distinct from a knowledge graph (too generic), a call graph (too narrow), and code search (different layer). It is the same primitive LSP serves to IDEs, with an agent-shaped query surface on top.
Why doesn’t LSP solve this for AI agents?
LSP is cursor-position-shaped; agents work in symbol space. LSP responses are single-call and positional; agents need batched, semantic, recency-aware queries. LSP servers are tuned for IDE memory pressure, not whole-codebase navigation. LSP is a usable substrate underneath but not a usable surface above. Wrap it in an agent-facing tool layer, or build a parallel index.
Do I need code-intelligence MCP or some specific product?
No, but pick by measured cost on your own questions, not by category narrative. On the R005 40-Q two-repo bench, code-intelligence beats default on judge by +0.82 and ties CodeGraph on judge while being meaningfully more citation-accurate (mech 0.426 vs 0.331). The difference between the two graph products is not the index size or the transport. It is what each retrieval response actually returns and how reliably its citations resolve. Build it, buy it (GitNexus, CodeGraph, Sourcegraph Cody, code-intelligence MCP, Aider’s repo map), or wrap LSP with a thin verb layer; just verify the win on your repo before you trust the README.
How much does indexing cost?
Index build is a one-time cost per repo edit batch, paid by the daemon and not by the agent. CodeGraph (tree-sitter only) indexes most repos in seconds and stays in incremental-rebuild via filesystem watches. Code-intelligence indexes a Django-sized codebase in roughly a minute cold, with incremental rebuilds in seconds. Index cost is not on the critical path of agent latency in either case; the per-query story above is what dominates.
What this changes for the agents I run
Naming the project graph as a primitive is not a product pitch. It is a precondition for noticing that filesystem-shaped tools were a borrowed abstraction from IDEs that does not fit how coding agents actually work. The borrow was reasonable when “AI assistant” meant “autocomplete in the IDE.” It is no longer reasonable when the agent runs unattended for hours, fans out to subagents, and makes decisions you find out about later. At that scale, the per-turn cost of reconstructing the graph by hand is the bill you pay for using the wrong abstraction.
The R005 bench says the abstraction win is real but narrower than the marketing version. On 40 questions across two repos, code-intelligence beats default Claude Code on judge (+0.82) and wall time (29 percent faster) for an 8 percent token premium. It ties CodeGraph on judge while being 19 percent cheaper and far more citation-accurate. Both graph products beat default on five of six task types; default genuinely wins on impact analysis. The graph’s primary value is the floor it puts under hard questions (architecture, concept, multi-hop, negative cases) where filesystem-shape fails catastrophically, not edging out grep on the easy ones.
Three things follow.
First, the abstraction works, with a smaller engineering payload than expected. The configuration carrying the +0.82 judge gap is hybrid BM25 + vector retrieval with RRF (Reciprocal Rank Fusion) plus a structural-ranking pass that respects the graph’s own shape (definitions over usages, signatures over body lines). No exotic ML in the critical path. The graph win comes from getting the shape right, not from piling weight on top.
Second, citation accuracy is a different metric than judge approval, and it matters more than it looks. CodeGraph and code-intelligence land within noise on the judge means, but mech 0.426 vs 0.331 and citation-hit 50 percent vs 32 percent is a real gap. Hallucinated file:line cites are the failure mode that becomes expensive once an agent acts on them autonomously: the answer reads plausibly, the next step trusts it, and the agent edits a file that does not contain the symbol it thinks it does. If you’re picking between graph products that tie on judge, pick the one whose mech score is higher.
Third, the practical posture for picking a tool: run the filesystem tools by default, reach for a measured graph product when the question shape is the kind grep fails catastrophically on (architecture summaries, concept queries, “does this exist in the codebase?”, multi-hop tracing through unfamiliar code). On impact analysis, the bench currently says stick with the filesystem. Pick by question shape, pick by measured cost on your own questions, pick honestly. The graph wins where it wins; the filesystem still wins where it wins. Decide which workload you actually have before you decide which tool to wire up.
If it was useful, pass it along.
