The Promotion Ladder: Prompt, Skill, Hook, Tool
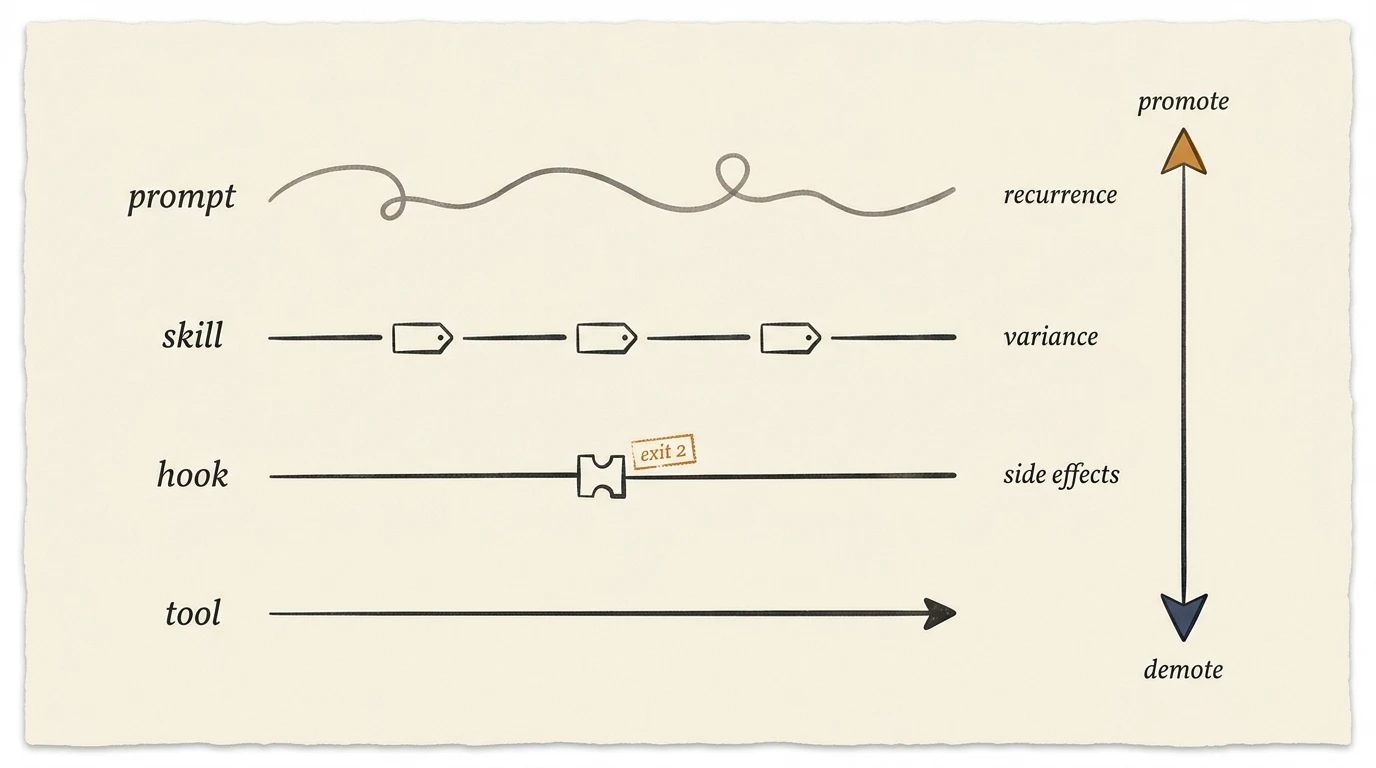
If you have written the same prompt three times, you have already built a skill. You just have not noticed yet. Three times is necessary; it is not sufficient. A prompt that recurs 50 times but evolves each sprint belongs at the skill rung. A prompt that recurs 3 times with credential-exposure side effects belongs at the hook rung immediately. Recurrence is one of three dimensions, not the whole criterion.
AGENTIF benchmarked 707 human-annotated instructions across 50 real-world agentic applications and found “the best-performing model only follows fewer than 30% of the instructions perfectly” (arXiv 2505.16944, 2025). Datadog’s April 2026 production-trace analysis found 69% of all input tokens are system prompts and only 28% of spans use the 90%-discount prompt cache (Datadog State of AI Engineering 2026). At those numbers, a repeated prompt is the most flexible, the most expensive, and the least reliable place to put load-bearing behavior. Four rungs trade flexibility for determinism. Prompt is request. Skill is structured request. Hook is enforcement on event. Tool is enforcement on call. The decision is rung-matching, not rung-racing.
Key Takeaways
- AGENTIF (Tsinghua KEG, NeurIPS 2025) found the best frontier model follows fewer than 30% of agentic instructions perfectly across 707 instructions (arXiv 2505.16944, 2025).
- Datadog’s State of AI Engineering 2026 measured 69% of production input tokens as system prompts; only 28% of spans use the 90%-discount prompt cache (Datadog, 2026).
- Microsoft’s agent-skills progressive-disclosure research found a 132-skill catalog costs ~13,900 tokens for a typical session versus 100,000+ for naive loading, an 86% reduction (Microsoft Agent Skills, 2026).
- Naive MCP costs 1.3x to 80x more tokens than CLI for identical tasks; well-designed schema (Cloudflare Code Mode) cuts the same workload 99.9% (Scalekit, 2026; Cloudflare, 2026).
Why should repeated prompts graduate?
The prompt rung is the most flexible, the most expensive, and the least reliable place to put load-bearing behavior. AGENTIF measured the best-performing model at under 30% perfect adherence across 707 agentic instructions (arXiv 2505.16944, 2025); Datadog measured 69% of production input tokens as system prompts and only 28% of spans using the 90%-discount prompt cache (Datadog, 2026). A repeated prompt re-sends the same instruction on every call and pays the variance tax every time.
The structural cost of staying at rung-1 compounds. Datadog’s data is the strongest public number on the system-prompt token share; 69% means rung-1 is the structurally majority cost at scale. The cache half-step is the lowest-friction optimization available, and it goes unused 72% of the time. A 90% discount on cached input tokens is sitting on the table for most teams (Anthropic pricing, 2026). That is the half-step between pure prompt and skill that most teams skip on the way somewhere they need not go.
The variance floor matters more than the cost floor. Even at temperature 0, prior work cited in the Stability Trap paper shows up to 15% variance across identical runs; the paper’s own reasoning-stability measurement on quantitative tasks is 19% (arXiv 2601.11783, 2026). The prompt rung does not become deterministic by tuning temperature. It becomes deterministic by changing rungs.
The killer hook restates and complicates itself. Ken Huang’s heuristic is “if you have typed the same set of instructions more than three times, it is a catastrophic waste of your time” (Huang, 2026). That is one signal. It is not the only signal. A task that recurs 50 times but evolves each sprint belongs at the skill rung; a task that recurs 3 times with external side effects belongs at the hook rung immediately. Recurrence is the necessary condition, not the sufficient one.
The AGENTIF error breakdown points at the failure modes graduation actually fixes. Disallowed tool usage and omission of required tools are the most common error classes; incorrect condition checks account for above 30% of errors. These are precisely the failure modes that rung-3 eliminates structurally, not by retry. A PreToolUse hook that refuses an action does not depend on the model remembering not to take it.
Citation capsule: AGENTIF benchmarked 707 instructions across 50 real-world agentic applications and found the best-performing model follows fewer than 30% perfectly (arXiv 2505.16944, 2025). Datadog’s State of AI Engineering 2026 measured 69% of production input tokens as system prompts with only 28% of spans using the 90% prompt cache (Datadog, 2026). The prompt rung is structurally the highest-cost, highest-variance place to put recurring behavior. The rung-1 economics deep-dive quantifies what the half-step buys before graduation.
What are the four rungs of the promotion ladder?
Four rungs trade flexibility for determinism in order. Rung 1, prompt (flexible): a natural-language instruction re-sent on every call, including CLAUDE.md, AGENTS.md, and direct user prompts, with highest variance and highest amortized token cost. Rung 2, skill (structured-advisory): a progressive-disclosure markdown bundle with a routing description and a body that loads on trigger; Microsoft’s agent-skills research measured 86% token reduction on a 132-skill catalog versus naive loading (Microsoft Agent Skills, 2026).
Rung 3, hook (deterministic-gated): shell commands, HTTP endpoints, or LLM prompts that fire on lifecycle events, with current Claude Code docs listing 29 distinct events across 9 categories and the only rung where exit code 2 blocks unconditionally (Claude Code hooks reference, 2026). Rung 4, deterministic tool (fully-deterministic): an MCP server or CLI tool; the MCP registry grew from approximately 2,000 servers in November 2025 to 9,400+ by April 2026, a 7.8x year-over-year growth (Digital Applied, 2026). Together they form what this post will call the promotion ladder.
The cost-and-variance spectrum has an Anthropic-official articulation. The best-practices reference is precise: “An instruction like ‘never edit .env’ in CLAUDE.md is a request, not a guarantee. A PreToolUse hook is enforcement” (Anthropic best-practices, 2026). Generalize across all four rungs. Rung-1 is request. Rung-2 is structured request with progressive loading. Rung-3 is enforcement on event. Rung-4 is enforcement on call. Each step removes one degree of model interpretation from the loop.
The pre-emptive caveat against rung-racing is empirical, not stylistic. Scalekit’s 75-task GitHub-API head-to-head found naive MCP costs 1.3x to 80x more tokens than CLI for identical tasks (get-repo-info: 1,365 versus 27,313 tokens, a 20x overhead; summarize-PRs: 4,998 versus 400,013, an 80x overhead). The monthly cost projection landed at $3.20 CLI versus $55.20 MCP for an equivalent workload, a 17x multiplier (Scalekit, 2026). Apideck documented a three-MCP-server setup consuming 143,000 of 200,000 available tokens (72%) before any conversation started (Apideck, 2026). Premature graduation to the tool rung is the most expensive failure mode of the entire ladder, and “race to the bottom rung” is the strawman to refute first, not last.
The flip side rescues the rung. Well-designed tool-rung schema can cut MCP token cost 99.9%. Cloudflare’s Code Mode wrapped a 2,500-endpoint API as two tools (a search and an execute) backed by a sandboxed V8 isolate, reducing projected per-call cost from approximately 1.17 million tokens to approximately 1,000 tokens (Cloudflare, 2026). Rung-4 cost is a function of schema design, not an inherent property of the rung. The ladder is a cost-and-variance spectrum, and the operational principle is rung-matching, not rung-racing: deploy each repeated task to the rung where the stability of that task and the cost of variance match.
The named labels are intentional. They are the rung labels this post will use as plain phrasing from here on: flexible (rung 1), structured-advisory (rung 2), deterministic-gated (rung 3), fully-deterministic (rung 4). The rung-2 deep-dive, the rung-3 substrate, and the rung-4 design discipline each sit on a single rung; the value of naming the ladder is that the cross-rung decision becomes legible.
Citation capsule: Four rungs trade flexibility for determinism. Anthropic’s best-practices reference frames the cost-and-variance spectrum: “an instruction in CLAUDE.md is a request, not a guarantee. A PreToolUse hook is enforcement” (Anthropic, 2026). Generalize across all four: rung-1 is request, rung-2 is structured request, rung-3 is enforcement on event, rung-4 is enforcement on call. The promotion ladder is a cost-and-variance spectrum, not a feature menu.
When should I promote a prompt to a skill?
The promotion criterion has three dimensions, not one. Recurrence count: the same intent recurs more than three times within a working window. Variance tolerance: the cost of a wrong execution is bounded, meaning a revertible diff, no external state mutation, no customer-facing artifact. Side-effect surface: actions stay within the agent’s reasoning, not the working tree or external systems. When all three pass, promote to a skill. When any single dimension breaches threshold (high recurrence paired with external side effects, for instance), skip rung-2 and promote directly to rung-3 or rung-4. Recurrence alone is necessary, not sufficient.
The skill rung is structured-advisory, not deterministic. Skills route via description, load the body progressively, and remain interpretable by the model. The promotion gate is not “did I extract the prompt.” It is “did I write a description that routes reliably.” That sentence is the entire difference between the rung-2 graduation working and rung-2 graduation failing.
The quality failure mode at rung-2 is empirical. SkillReducer’s analysis of 55,315 publicly available skills from GitHub found 26.4% completely lack routing descriptions, 44.1% have inadequate descriptions under 20 tokens, and only 38.5% of skill body content is actionable core rules; 40.7% is background prose and 12.9% is examples (arXiv 2603.29919, 2026). Mechanical extraction is not promotion. Rung-2 demands authoring discipline.
The cost case for graduation is the strongest argument once the discipline is in place. Microsoft’s progressive-disclosure research found Tier-1 metadata costs 50 to 100 tokens per skill; a 132-skill catalog costs approximately 10,000 tokens at startup, with two activated skills adding approximately 3,900 tokens, totalling approximately 13,900 tokens for a typical session versus 100,000+ tokens for naive full loading (Microsoft Agent Skills, 2026). That is an 86% reduction. The skill rung is structurally cheaper than the prompt rung when the catalog grows, and the savings compound across sessions.
The architectural maturity for rung-2 graduation landed inside one quarter. Anthropic launched Skills on October 16, 2025 (claude.com/blog/skills); published Agent Skills as an open standard on December 18, 2025 with seven partners (Atlassian, Canva, Cloudflare, Figma, Notion, Ramp, Sentry) (Anthropic Engineering); and shipped the March 3, 2026 skill-creator update with automated description optimization that tests 20 synthetic prompts per skill, applied to Anthropic’s own 6 built-in document skills and improving triggering on 5 of 6. The tooling exists. The discipline is the part teams still own.
The three-dimensional criterion runs as a short decision function:
def select_rung(recurrence: int, variance_tol: str, side_effect: str) -> str:
# recurrence: integer count within a working window
# variance_tol: "high" (revertible) | "medium" | "low" (unrecoverable)
# side_effect: "reasoning" | "working_tree" | "external"
if side_effect == "external" and variance_tol == "low":
return "tool" # rung 4: must do the work, not gate it
if variance_tol == "low":
return "hook" # rung 3: unconditional enforcement
if recurrence > 3 and side_effect != "external":
return "skill" # rung 2: structured-advisory
return "prompt" # rung 1: flexible defaultThe thresholds are the empirical floor. Tune them against the team’s failure history; the shape is the contribution.
The decision diagram doubles for the next two sections. The middle decision node is the same; the threshold values change with the rung. The rung-2 deep-dive covers the description-quality gate in detail; the criterion above is the upstream choice that decides whether the team has graduated to that gate.
Citation capsule: Promotion is a three-dimensional criterion. Recurrence count alone is necessary; not sufficient. SkillReducer’s analysis of 55,315 public skills found 26.4% lack routing descriptions and 44.1% have descriptions under 20 tokens (arXiv 2603.29919, 2026). The rung-2 gate is not “did I extract the prompt.” It is “did I write a description that routes reliably.” Mechanical extraction is not promotion; authoring discipline is.
When should I promote a skill to a hook?
Promote a skill to a hook when the behavior must execute unconditionally on a specific lifecycle event, not when the model decides it should. The hook rung is the only Claude Code primitive that runs as code on every matched event regardless of model reasoning, with exit code 2 blocking the event unconditionally (Claude Code hooks reference, 2026). Skills cannot do this. CLAUDE.md cannot do this. If the cost of a missed execution is non-negligible (security gate, audit log, mandatory test run before commit), the behavior belongs at rung-3.
The hook event surface defines what behaviors can be made unconditional. Current docs list 29 distinct hook event types across 9 categories: session lifecycle (SessionStart, Setup, SessionEnd); user input (UserPromptSubmit, UserPromptExpansion); tool execution (PreToolUse, PostToolUse, PostToolUseFailure, PostToolBatch, PermissionRequest); permission handling (PermissionDenied, Elicitation); agent and subagent lifecycle (SubagentStart, SubagentStop, TaskCreated, TaskCompleted); team and idle (TeammateIdle, Stop); error (StopFailure); configuration and file (ConfigChange, CwdChanged, FileChanged, InstructionsLoaded); and context management (PreCompact, PostCompact). The surface is large enough that most load-bearing behaviors can be wired to it.
The Anthropic-official articulation is the sharpest version of the rung transition. “An instruction like ‘never edit .env’ in CLAUDE.md is a request, not a guarantee. A PreToolUse hook is enforcement” (Anthropic best-practices, 2026). The rung-2-to-rung-3 promotion is precisely the transition from request to enforcement. The behavior is the same shape; the substrate changes.
The cost of the rung-3 graduation is small and measurable. Blake Crosley’s April 2026 audit documents 95 hooks distributed across 6 lifecycle events with approximately 200ms total overhead per event (blakecrosley.com, 2026). 200ms is negligible for the determinism guarantee. The maintenance overhead is real, and it is the entry point for the demotion discussion below; the latency cost is not the constraint.
The side-effect surface is the load-bearing axis. A linting check on a saved file is rung-2 (advisory, easy to override). A pre-commit ban on editing .env is rung-3 (unconditional, no override). The behavior is structurally the same shape; the side-effect surface (linter advisory versus credential exposure) determines the rung. If the agent could discover a workaround, you are at the wrong rung.
The cross-cluster claim closes the section. Hooks are also the substrate that threshold checkpoints, audit-log enforcement, and pre-execution policy gates land on. The rung-3 substrate post maps the toolkit; this post specifies the promotion criterion that loads work into it. If the team is already investing in any of those use cases, the rung-3 graduation is already underway, and the promotion criterion is whether to formalize it.
Citation capsule: The rung-3 distinction is unconditional-on-event. Claude Code hooks expose 29 distinct lifecycle events across 9 categories (Claude Code hooks reference, 2026); exit code 2 blocks the event unconditionally. Anthropic’s own articulation: an instruction in CLAUDE.md is a request; a
PreToolUsehook is enforcement (Anthropic, 2026). Skills do not have this property. Promote when the cost of a missed execution is non-negligible.
When should I promote a hook to a deterministic tool?
Promote a hook to a deterministic tool (MCP server or CLI tool) when the behavior is itself the work, not the gate around the work. A hook checks; a tool does. When the action is a complete unit (run the test suite, deploy the service, fetch repo metadata) and the model’s role is to choose when to invoke it rather than to author it, the behavior belongs at rung-4. Berkeley Function Calling Leaderboard V4 puts average tool-call accuracy at 71.7% with top performers at 88.5% (gorilla.cs.berkeley.edu/leaderboard, 2025-2026); substantially higher than the under-30% adherence at rung-1, but not 100%. The rung is more deterministic, not perfectly deterministic.
The schema-design dependency is the load-bearing constraint. GitHub’s Copilot team cut the default tool set from 40 to 13 based on usage statistics. The online A/B test result was a 400ms reduction in average response latency and a 190ms reduction in time-to-first-token. The offline benchmark result was a 2 to 5 percentage-point improvement in SWE-Lancer and SWEbench-Verified success rates across GPT-5 and Sonnet 4.5. Embedding-based dynamic tool selection achieved 94.5% coverage versus 87.5% for LLM-based and 69.0% for static default (GitHub Engineering, 2026). Fewer, better-defined tools outperform more tools on both latency and accuracy.
The cost-design dependency cuts both ways. Scalekit’s 1.3x to 80x MCP-vs-CLI overhead is the worst case; Cloudflare’s 99.9% reduction (1.17M to approximately 1,000 tokens per call via the search and execute two-tool design backed by a V8 isolate) is the best case (Cloudflare, 2026). Rung-4 cost depends entirely on schema discipline. The tool rung is not automatically cheaper than rung-1, but it can be 1,000x cheaper if the schema is correct.
The production-blocker mapping closes the empirical case. LangChain’s State of Agent Engineering 2026 found 57.3% of respondents have agents in production (67% of 10,000+ employee organizations) with 32% citing quality and consistency as their top blocker; 89% have observability implemented, only 52.4% run offline evaluations, a 37-point gap (LangChain, 2026). Quality and consistency blockers are precisely what rung-4 with disciplined schema design eliminates: a deterministic tool with a tight signature does not exhibit “almost right but not quite” output the way a prompt does.
The market signal corroborates the direction. Datadog’s State of AI Engineering 2026 reports agent framework usage rose from more than 9% of organizations in early 2025 to almost 18% by the beginning of 2026, growth consistent across startups, mid-market, and enterprise (Datadog, 2026). The market is graduating behaviors to the tool rung; the open question is whether the schema discipline is graduating with it.
Simon Willison’s counter-argument deserves a fair citation. “Almost everything you might achieve with an MCP can be handled by a CLI tool; LLMs know how to call cli-tool —help, which means you don’t have to spend many tokens describing how to use them” (Willison, 2025). The resolution is on the rung definition, not against it. CLI tool and MCP are both rung-4 surfaces. CLI is the cheaper one when the surface is local and the tool exposes --help. MCP is the right one when the surface crosses process or network boundaries with structured outputs. Both are fully-deterministic; pick the surface that fits the side-effect topology.
The chart compresses the rung-4 thesis into one image. Two implementations of the same problem land three orders of magnitude apart. Schema design is the variable; the rung is not. The rung-4 design discipline post walks the schema discipline in detail; this post specifies the upstream decision to graduate the work there at all.
Citation capsule: Rung-4 cost is a schema property, not a rung property. Cloudflare’s two-tool Code Mode design (search and execute over a V8 isolate) cut a 2,500-endpoint API from approximately 1.17M tokens per call to approximately 1,000, a 99.9% reduction (Cloudflare, 2026). BFCL V4 puts average tool-call accuracy at 71.7% with top performers at 88.5% (Gorilla, 2026). Fewer, better-defined tools outperform more tools on both latency and accuracy.
When should I demote a rung?
The ladder runs both directions. Demote a hook back to a skill when false-positive rates exceed the team’s tolerance (rule of thumb: above 5% of triggered events) or when the underlying behavior is changing fast enough that the hook surface itself becomes a maintenance burden. Demote a skill back to a typed prompt template or a CLAUDE.md rule when the trigger description has decayed to vagueness; SkillReducer found 26.4% of public skills already meet that criterion at authoring time (arXiv 2603.29919, 2026). Demote a deterministic tool to a hook when the work has shifted from autonomous execution to gating, or when schema overhead is consuming a measurable fraction of the context window.
The no-one-writes-this gap deserves direct naming. Every existing post on the four primitives is about adding them. Anthropic’s docs, MindStudio’s framework (mindstudio.ai, 2026), Dotzlaw’s hooks post (dotzlaw.com, 2025), Willison’s skills post (Willison, 2025), Praison’s three-layer comparison (mer.vin, 2026): all unidirectional. The demotion path is unaddressed in the published literature. This is the post’s largest original contribution.
The demotion signals are concrete and observable. A hook firing too often produces structured rejections the agent cannot reason around; the agent sees a failure mode it cannot diagnose. A skill with a vague description fails to route, costing description-tier tokens (50 to 100 per skill at startup) with no body-tier activation. A tool whose schema consumes 70%+ of the context window (Apideck’s 143K-of-200K finding) is reverse-economical compared to a CLI invocation through Bash for the same task (Apideck, 2026).
The demotion-criteria checklist runs as a few lines of config:
demotion_criteria:
rung_4_to_rung_3:
schema_pct_of_context_window: "> 70%"
schema_authoring_cost_per_quarter: "> 1 engineer-week"
work_has_shifted: "execution -> gating"
rung_3_to_rung_2:
false_positive_rate: "> 5% of triggered events"
underlying_behavior_change_rate: "> 1 change / sprint"
rung_2_to_rung_1:
routing_description_length_tokens: "< 20"
body_actionable_fraction: "< 0.4"
activations_per_week: "< 1"Why demotion is not failure: the four rungs are complementary, not sequential. The team writing demotion criteria is the team doing rung-matching. Demotion is the operational acknowledgment that the stability of the work changed. It is the falsifiability mechanism that makes the ladder a model rather than a slogan. A team that only adds is not doing the discipline; they are decorating it.
The connection to the substrate is direct. The rung-3 substrate documents the surface; this post documents the conditions under which to add to it and remove from it. The two are paired: substrate is the surface, ladder is the policy. The orchestration substrate is where demotion decisions land in practice, because the subagent topology determines what behaviors are easy to walk back.
Citation capsule: The ladder runs both directions. Demote a hook when false-positive rates exceed 5%, a skill when its description decays below 20 tokens (SkillReducer found 26.4% of public skills already meet that bar at authoring time per arXiv 2603.29919, 2026), a tool when its schema consumes a measurable fraction of the context window. The four rungs are complementary, not sequential; the team writing demotion criteria is the team doing rung-matching.
How do I apply the ladder to a real workflow?
I have walked this trajectory more than once across my own projects, and the cleanest run was on Pylon’s lint enforcement. The starting behavior was a CLAUDE.md sentence: “before any commit, run the lint suite and refuse to commit if there are errors.” Recurrence count: every commit. Variance tolerance: low; silent lint failures ship broken code. Side-effect surface: external; the commit lands in shared history. Three-dimensional promotion: skip the rung-2 evaluation as the primary surface, promote directly to rung-4 as a CLI tool, gated by a rung-3 PreToolUse hook for the safety net.
The trajectory was short. At day 0, the behavior was a CLAUDE.md sentence (rung-1). Recurrence count climbed past three within the first day. Variance tolerance verified low when the first un-linted commit blocked CI for everyone on the team. I wrote a bin/lint CLI tool with two flags (rung-4) and a PreToolUse hook on the Bash tool that runs bin/lint --staged and exits 2 on failure (rung-3). The skill rung was skipped because the behavior is unconditional, not advisory. Recurrence-only thinking would have ended at rung-2; the three-dimensional criterion routed straight past it.
The worked-example test arrived six months later. I added an experimental linter that catches a new class of issues but has a 12% false-positive rate on the existing codebase. Promotion criterion failed on variance tolerance. The new behavior landed as a skill (rung-2) with a routing description tested via the March 2026 skill-creator update, not as a hook (Anthropic, 2026). When the false-positive rate eventually drops below 1%, the skill is the candidate for a second PreToolUse hook layer. The graduation step is conditional on the variance-tolerance dimension, not on time elapsed.
The demotion arc landed two quarters later. The language toolchain shipped a built-in formatter that superseded the first linter. The rung-3 hook was demoted: removed from the hook layer, retained as a skill new contributors can still invoke explicitly during onboarding. The rung-4 CLI tool stayed as a deterministic invocation surface for CI. The ladder rebalanced.
The rung-matching summary closes the example. The trajectory was not “race to MCP.” It was three promotions and one demotion across two quarters, driven by the stability of the underlying work, not by maturity ambition. Running the ladder both directions is what gets you the cost and variance benefits without the maintenance penalty. The spec-driven workflow this ladder lives inside and the human-side delegation decision that fires four days before this post are the two operational frames the rung selection sits between.
Citation capsule: The worked example demonstrates rung-skipping by design. A behavior with low variance tolerance and external side-effect surface routes past rung-2 directly to rung-3 and rung-4. Six months later, a new behavior with a 12% false-positive rate lands as a skill rather than a hook; two quarters after that, a superseded hook is demoted back to a skill. Three promotions and one demotion in two quarters, driven by the stability of the underlying work.
FAQ
What is the difference between a skill and a hook?
A skill is structured-advisory: the model reads the routing description, decides whether to load the body, and follows the body’s instructions as part of its reasoning chain. A hook is deterministic-on-event: it executes as code (shell command, HTTP endpoint, or LLM prompt) at a specific Claude Code lifecycle event, with exit code 2 blocking the event unconditionally. Anthropic’s best-practices reference articulates it: “an instruction in CLAUDE.md or a skill is a request, not a guarantee. A PreToolUse hook is enforcement” (Anthropic, 2026).
Should I always graduate to the most deterministic rung?
No. Scalekit’s MCP-vs-CLI benchmark found naive tool-rung adoption costs 1.3x to 80x more tokens than CLI for identical tasks (Scalekit, 2026); Apideck documented three MCP servers consuming 72% of a 200K context window before any conversation (Apideck, 2026). Premature graduation is the most expensive failure mode of the entire ladder. The decision variable is stability of the work, not maturity of the team.
When should I demote a hook back to a skill?
Demote when false-positive rates exceed the team’s tolerance (rule of thumb: above 5% of triggered events) or when the underlying behavior is changing fast enough that the hook surface becomes maintenance overhead. Blake Crosley’s 95-hook audit documents the upper bound of a one-person hook layer at approximately 200ms per event (blakecrosley.com, 2026); above the false-positive threshold, demotion is operationally cheaper than re-tuning.
Where does CLAUDE.md fit in the ladder?
CLAUDE.md is rung-1 advisory: a persistent project-root markdown file that gives agents instructions without adding tokens to every message. AGENTS.md is the cross-vendor equivalent governed by the Agentic AI Foundation under the Linux Foundation as of January 2026 (agents.md). Both are rung-1 because they remain interpretable by the model and have no deterministic enforcement. The Anthropic best-practices reference is explicit that instructions in CLAUDE.md are requests, not guarantees.
Conclusion
The four rungs trade flexibility for determinism. The prompt rung is the most flexible, the most expensive, and the least reliable place to put load-bearing behavior; AGENTIF measured the best frontier model at under 30% perfect adherence and Datadog measured 69% of production input tokens as system prompts (arXiv 2505.16944, 2025; Datadog, 2026). The decision is rung-matching, not rung-racing. Scalekit’s 1.3x to 80x MCP-vs-CLI overhead and Cloudflare’s 99.9% schema-design reduction are the two endpoints of the rung-4 cost spectrum (Scalekit, 2026; Cloudflare, 2026). Promotion is a three-dimensional criterion: recurrence count, variance tolerance, and side-effect surface. Ken Huang’s “three times” is the lower bound on dimension one, not the full criterion. Hooks are the only rung where exit code 2 blocks unconditionally across 29 lifecycle events (Claude Code hooks reference, 2026); the rung-2-to-rung-3 transition is the move from request to enforcement. Demotion is rung-matching in reverse; it is the falsifiability mechanism that makes the ladder a model rather than a slogan. The Wave 2 cluster covered the four primitives in isolation; this post named the architecture they form.
Apply the three-dimensional criterion to the top three repeated prompts on your team’s CLAUDE.md this week. Demote any rung-3 hook with a false-positive rate above 5%. Resist the urge to race to rung-4 without schema discipline. The machine-side delegation decision is the human counterpart this ladder’s automation runs alongside; the spec-driven workflow is the orchestration substrate the ladder lives inside. The rungs are complementary, not sequential. Match the work to the rung; let the work tell you when to move.
If it was useful, pass it along.
