The Session Handoff: When Your Attention Budget Is Spent
The session has been running four hours. The plan re-orders itself for the third time. The agent re-reads a file it read at turn 12. You spawn a subagent to “free up context”. The subagent returns its summary into the same saturated attention. Nothing got better.
Anthropic frames context as an attention budget, not a token buffer: a finite resource with diminishing marginal returns (Anthropic Engineering, Sep 29 2025). The 2026 Agentic Coding Trends Report extends that into a load-bearing 2026 skill claim. Lost-in-the-middle studies measure 30%+ accuracy drop on mid-context retrieval; an 18-model 2025 benchmark including GPT-4.1, Claude Opus 4, and Gemini 2.5 found Claude decays slowest but no frontier model is immune (arxiv 2510.10276, 2025). Claude Code’s auto-compact defaults around 95% of window capacity (Morph, 2026), but the practical quality cliff arrives much earlier, around 50% fill (MindStudio, 2026). The 1M context is real; the useful 1M context is not.
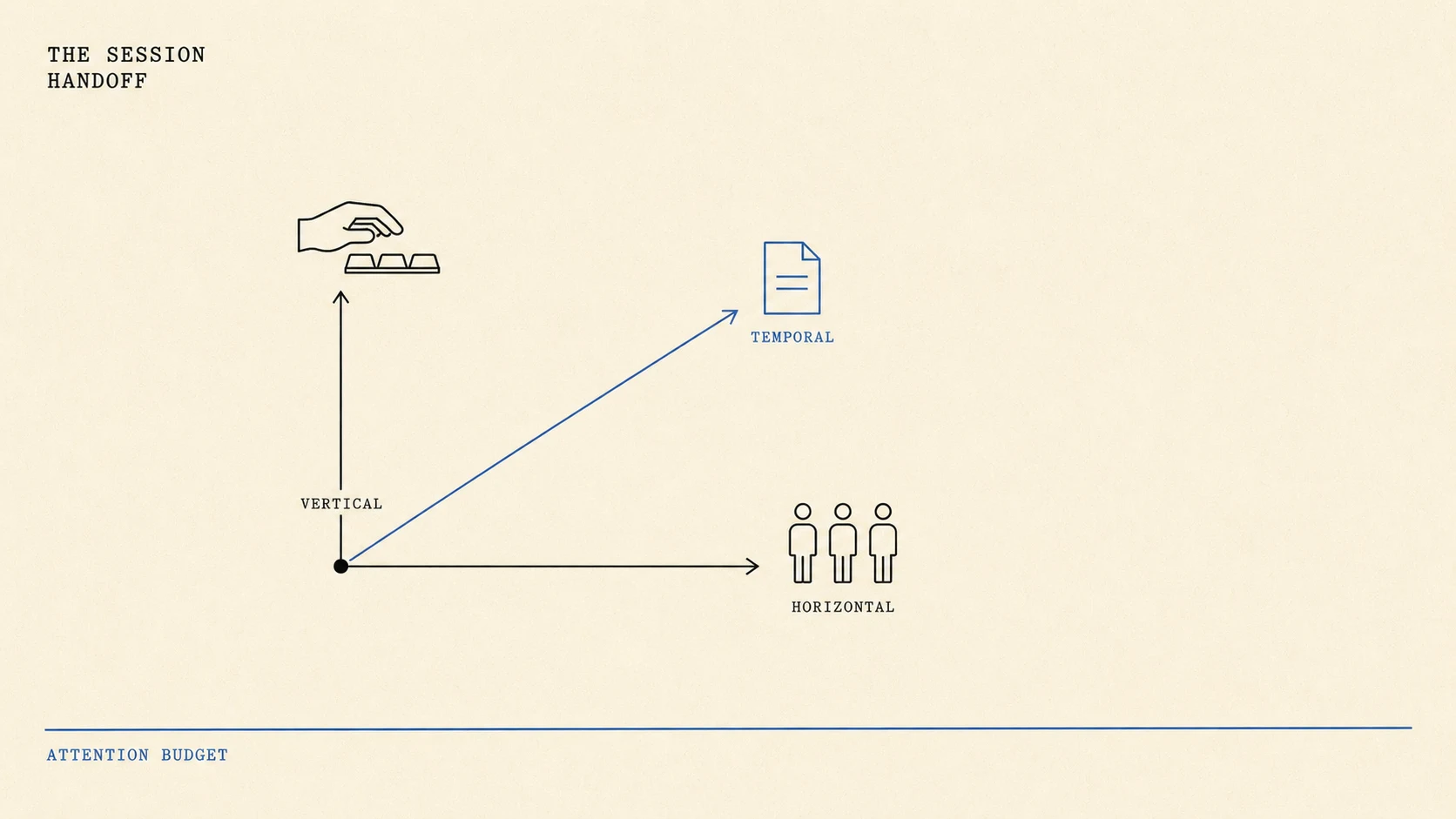
Handoff is not one thing. It is three orthogonal moves, one per budget. Vertical handoff (human takes the keyboard back) spends judgment. Horizontal handoff (parent spawns subagents) spends tokens. Temporal handoff (session N hands off to session N+1) spends nothing the others touch; it spends the attention the parent has already saturated. Each fixes a different problem. They are not substitutes.
This post names the third axis, defines the attention budget, gives five observable triggers for session reset, specifies a four-field handoff artifact that survives the cut, contrasts fan-out’s failure mode against it, and closes with the decision tree for picking the right axis when an agent stalls.
Key Takeaways
- Anthropic frames context as a finite attention budget, not a token buffer (Anthropic, Sep 29 2025). The 2026 Agentic Coding Trends Report names it the load-bearing 2026 skill.
- Frontier LLMs lose 30%+ retrieval accuracy on mid-context information; all 18 tested 2025 frontier models degraded with length, Claude slowest (arxiv 2510.10276, 2025).
- Multi-agent fan-out uses roughly 4-7x more tokens than single-agent sessions, and Agent Teams (Feb 2026 experimental) runs at roughly 15x (Claude Code sub-agents docs, 2026). It buys tokens, not attention.
- Quality degrades at roughly 50% context fill, well before auto-compact’s ~95% threshold (MindStudio, 2026). Reset at half the limit, not at the limit.
Why is handoff three axes instead of one?
Handoff is the move you make when the current configuration of human-plus-agent-plus-context cannot complete the next step well. There are three orthogonal versions, distinguishable by what the move spends.
Vertical handoff is human-to-agent or agent-to-human along the judgment axis. Anthropic’s 2026 trends report measures the gap directly: developers use AI in roughly 60% of work but fully delegate only 0-20% of tasks (Anthropic, 2026). The decision is calibrated, not binary; cues fire and the human reclaims the keyboard. The cues, the recovery shape, and the “almost right” failure mode that drives them live in The Agent Handoff Problem.
Horizontal handoff is parent-to-subagent along the token axis. Each sub-agent in Claude Code gets a fresh 200K context window (Anthropic, 2026); concurrency caps at ten per orchestrator. Net effective working memory expands. Net token cost rises 4-7x for standard fan-out and roughly 15x for the experimental Agent Teams variant (dev.to, 2026; MindStudio, 2026). The spawn-vs-stay decision tree lives in Subagent Patterns: Spawn vs Stay.
Temporal handoff is session-to-session along the attention axis. The session boundary is the only move that resets the parent’s attention state. /clear cuts cleanly inside the same terminal; /compact lossy-summarises and continues; a fresh terminal session adds a re-read of CLAUDE.md and drops accumulated process state (Claude.com, 2026). The community vocabulary collapses these into “context management”. This post separates them and treats the cut itself as the operational unit.
The three are orthogonal: each fixes a problem the others cannot. Burning subagents on an attention-saturated parent does not fix the parent; the subagents’ summaries arrive into the saturation. Asking a human to take the keyboard back when the issue is plan thrash from a four-hour session does not fix the thrash; the human inherits the same context. Resetting the session when the actual problem is a Tier 3 action you would not have approved does not fix the judgment gap; the new session will repeat the move.
Each axis below gets its own H2: the attention budget defined, the five triggers that say cut now, the four-field artifact that survives the cut, and the contrast that explains why fan-out is not a substitute.
What is the attention budget?
“Attention budget” is Anthropic’s term; this post extends it into an operational definition. The budget is the finite cognitive bandwidth a transformer applies to the tokens currently in its window. Capacity is not the same as quality: a 1M-token window does not buy 1M tokens’ worth of effective attention. Anthropic’s framing is explicit: “Like humans, who have limited working memory capacity, LLMs have an attention budget that they draw on when parsing large volumes of context” (Anthropic Engineering, Sep 29 2025). The substrate is finite; the operating discipline is allocation.
The empirical data comes from lost-in-the-middle studies. Tokens at the beginning and end of the window receive disproportionately strong attention; tokens in the middle receive less. Retrieval accuracy drops by 30%+ when key information sits mid-context. An 18-model 2025 benchmark including GPT-4.1, Claude Opus 4, and Gemini 2.5 measured the curve across frontier models (arxiv 2510.10276, 2025; Morph, 2026). Claude Opus 4 decays slowest, but the curve is still U-shaped. Rotary Position Embedding (RoPE), used in most modern LLMs, introduces a decay effect that makes models attend more strongly to tokens at the beginning and end of sequences; the decay is structural, not a bug.
The practical cliff arrives well before the buffer overflows. Claude Code auto-compact defaults around 95% of window capacity, configurable via CLAUDE_AUTOCOMPACT_PCT_OVERRIDE (Morph, 2026); practitioners measure quality degradation at roughly 50% fill (MindStudio, 2026; claudefa.st, 2026). Albert Sikkema’s Apr 23 2026 post documents an explicit downgrade from a 1M window back to 200K for better behaviour, citing the same effect: smaller windows force earlier resets and the earlier resets buy back attention quality (Albert Sikkema, Apr 23 2026).
The two thresholds are pulling in opposite directions on purpose. Auto-compact is engineered to delay the cut as long as possible; the quality-aware cut is roughly half that. Reset at half the limit, not at the limit. Token cost and attention cost are two different ledgers: tokens are dollars, attention is correctness. This post is about the attention ledger. The cost story for the same fleet lives in Agent Cost as a Team Sport and Cache-Aware Prompting.
The implication is the bridge to the next section. Attention saturates well before the buffer overflows. The handoff signal is degradation, not exhaustion. You cannot read it off the token counter. You read it off the agent’s behaviour.
When should I start a new session?
The session-reset decision can be operationalised as five named triggers, each with an observable signature you can detect mid-run. The triggers are not thresholds on token count; they are behavioural signals that the attention budget is spent regardless of what the buffer says.
Trigger 1: re-derivation loop. The agent re-reads the same file, re-runs the same search, or re-asks the same clarifying question two-plus turns apart. The signature is repeat tool-calls with identical or near-identical arguments. The mechanism: the relevant prior content has dropped out of effective attention; the agent re-derives because it can no longer see it. Detect by scanning the recent tool-call log for repeat keys, or by hashing tool inputs across the session.
Trigger 2: plan thrash. The plan node count or order changes across consecutive turns without new information arriving. The signature is a plan-mode diff that adds, removes, or reorders steps in the absence of an external event. The mechanism: the agent’s working model of the plan is no longer stable in attention. Detect by hashing the plan structure each turn and flagging adjacent-turn deltas not preceded by tool results or user input.
Trigger 3: summary drift. The agent’s self-summary diverges from the session’s actual state. It omits a tool that ran, claims a decision that was reversed, or asserts a file state that has changed since. The signature is /context output or an auto-compact preview that misses material events. The mechanism: lossy mid-context attention; the agent summarises what it can still see, which is no longer the whole story. Spot-check the summary against the transcript before accepting a /compact; if the agent’s summary cannot be trusted to compress, it cannot be trusted to continue either.
Trigger 4: tool-output amnesia. The agent calls a tool that already ran in this session and treats the result as new. This is a sub-case of re-derivation but more diagnostic; the agent has not just re-run, it has lost the result. The signature is a tool call whose key matches an earlier call but whose follow-up reasoning treats the output as first-seen. The mechanism: the tool-output region has rotated out of effective attention. Maintain a tool-call index across the session and alert on repeats with identical keys.
Trigger 5: decision regression. A settled decision gets re-litigated as if open. The agent proposes an alternative to a choice already made and confirmed, without new evidence prompting the reopen. The signature is a turn that revives a closed question. The mechanism: the commitment state of decisions has degraded; the agent can see the choices but has lost the metadata about which one is current. Maintain an explicit decisions ledger (this is also the field-1 of the handoff artifact below) and flag turns that propose a non-current option.
The five triggers form a cheap, observable session-health eval that runs against transcript state, not internal model state. Two or more firing simultaneously is the strong reset signal; one firing is the weak signal that prompts the manual check. The triggers extend the failure-mode vocabulary from Autonomous Agent Failure Modes onto the session axis: context bleed lives mid-session in one run, but a re-derivation loop or summary drift lives across the boundary between sessions and is the canonical reason to draw a new one.
The triggers are also cheap to wire as hooks. A PostToolUse hook that maintains a tool-call cache and emits a warning on a repeat key catches triggers 1 and 4. A daily golden-prompt eval that compares the agent’s self-summary against the transcript catches trigger 3. Triggers 2 and 5 need a small extra ledger but the ledger is the same artifact the next H2 builds.
How do I write a handoff artifact that survives the cut?
A session handoff that survives the cut needs four fields. The community templates (jdhodges Claude Handoff Prompt, 2026; mejba.me Handoff Skill, 2026; who96/claude-code-context-handoff, 2026) cover the first three between them. The fourth (anti-goals) is the differentiator and the failure mode the others underspecify.
Field 1: decisions. What is settled. One bullet per decision: the choice and the one-line reason. The reason matters because the next session will re-read this without the conversational context that produced it. “Use PostgreSQL because we already have it in the stack” survives the cut. “Use PostgreSQL” does not, because the next session sees the choice without seeing the constraint that produced it.
Field 2: open questions. What is not settled. One bullet per question: the question, the candidate answers, and the one-line tie-break criterion. Without the tie-break, the next session re-opens the deliberation rather than resolving it. “Which retry policy? a) exponential, b) linear; tie-break: choose exponential unless the upstream is rate-limited per-minute, in which case linear” gives the new session enough to converge in one turn.
Field 3: anti-goals. What we have explicitly decided not to do, and why. This is the field that prevents decision regression (trigger 5 in the previous section). Without it, the new session reads the open questions and the decisions, sees no record that an alternative was rejected, and proposes the alternative again. The community templates gesture at it via “Never” lists (HumanLayer, Nov 25 2025) but do not name the failure mode it prevents.
Field 4: next action. Exactly one concrete step the next session begins with. Not a list. Not a status report. The single instruction that puts the new session straight into productive work, with the artifact loaded as ambient context. “Implement the retry policy chosen in field 1 against the client.ts adapter; first test goes in client.test.ts” is the shape; “continue the auth work” is not.
The artifact lives in a .handoff.md in the repo root or an appended block in CLAUDE.md for ongoing project work. It stays short by design (under 80 lines). It is not a substitute for CLAUDE.md or AGENTS.md; it is the per-task overlay. The substrate that loads CLAUDE.md on every session start is the substrate that ingests the handoff; the four fields ride the same machinery.
The first turn of the new session is a single message: “Read .handoff.md and proceed with the next action.” That message plus the file replaces the entire prior session’s working state. The mechanism is the same as a fresh CLAUDE.md read, plus the per-task overlay. The artifact is the operational unit; the session is the disposable carrier. The pattern shares its substrate with the cluster’s other handoff post (The Agent Handoff Problem) and with the context-surfaces decision in Context Engineering in Practice, but it specifies a smaller, opinionated shape that survives the cut without becoming documentation theatre.
The four-field shape is not the only shape that works. Larger artifacts work for larger handoffs (multi-day projects, multi-session features). The claim is that under this minimum, the handoff bleeds; over it, the discipline turns into ceremony.
A worked example for the auth refactor case:
# .handoff.md
## Decisions
- Use Better Auth, not custom JWT. Reason: BAA already in place; team familiar with the API.
- Session storage in PostgreSQL, not Redis. Reason: avoid the second datastore for v1.
## Open questions
- Refresh token rotation policy?
- Candidates: a) rotate every refresh, b) rotate once per session.
- Tie-break: choose (a) unless the mobile client cannot handle silent rotation.
## Anti-goals
- Do NOT add a new identity provider (we tried Auth0 last quarter; cost was the blocker).
- Do NOT touch the legacy `users` table schema. Migration is a separate phase.
## Next action
Implement the Better Auth client wiring in `src/lib/auth.ts`. First test goes in `src/lib/auth.test.ts` and asserts the BAA-compliant audit log entry.Why doesn’t fan-out fix attention saturation?
The instinctive move when a session feels heavy is to spawn subagents. The instinct is correct for the token-budget axis and wrong for the attention-budget axis. Each subagent gets its own fresh 200K context window (Anthropic, 2026); a fan-out across ten subagents nets roughly 2M tokens of working memory in parallel (MindStudio, 2026). What it does not do is reset the parent’s attention.
The mechanism is structural. Subagents return summaries to the parent’s context. The parent reads the summaries with whatever attention it has left. If the parent is already in lost-in-the-middle territory, the summaries land in degraded attention. The fan-out moved the work but not the attention. The parent sees clean summaries but cannot weigh them well; the model that could have written the summaries cannot now read them.
The cost makes the failure mode expensive. Fan-out runs at roughly 4-7x the token cost of single-agent sessions (dev.to, 2026); Anthropic’s Agent Teams experimental variant at roughly 15x. Spending 4-15x on the wrong axis is the failure mode the post is naming.
The diagnostic is short. If the trigger was “I need more eyes on parallel sub-tasks” or “I am running out of context budget for tool outputs”, fan-out is correct. If the trigger was any of the five attention-budget signals from the previous section, fan-out is the category error.
The published pattern for the horizontal axis (Subagent Patterns: Spawn vs Stay) gives the decision tree for spawn-vs-stay; this post adds the complementary claim that, even after the spawn decision is correct, the parent’s attention state still needs its own move. Two axes, two moves.
Given a stall, which axis applies?
The picker is three ordered questions.
First: did the agent take an action you would not have signed off on? Vertical axis. Take the keyboard back. See The Agent Handoff Problem for the cues and the recovery shape. The four named cues (confidence drift, scope creep, novel error class, 80% milestone) are calibrated against the same delegation-gap data Anthropic measures in the 2026 trends report.
Second: is the next sub-task independent and parallelisable, and is the bottleneck tool-output volume or sub-task time? Horizontal axis. Spawn subagents. See Subagent Patterns: Spawn vs Stay for the cost math and the cases where the 4-7x token multiplier is correct.
Third: are two or more of the five attention-budget triggers firing? Temporal axis. Reset the session. Write the four-field handoff artifact. Start fresh in a new terminal with the artifact pre-loaded as the first message.
The questions are ordered by reversibility. Vertical handoff is the cheapest to undo (the human can hand back in the next turn). Horizontal handoff costs tokens but the session state is preserved. Temporal handoff is the most expensive in continuity (the model loses everything not in the artifact); it is also the only move that actually resets attention.
The composite case is the one to watch. A single stall can fire more than one axis. If the agent is both proposing an action you would not sign off on and showing two attention-budget signals, the vertical reclaim is the visible move; the temporal reset is the silent move you make immediately after, before the next attempt. Do not keep working in saturated attention even after you have reclaimed the keyboard. The new session inherits the reclaim, not the saturation.
What does this change about long-running agents?
Long-Running Autonomous Agents: Drift, Checkpointing, Recovery frames drift as a property of the agent across a long run. METR’s Jan 29 update put Opus 4.6 at a 14.5-hour 50% horizon (METR, Jan 29 2026), with the horizon doubling every four months across 2024-2025. This post adds the human side: the human-plus-agent context window drifts as a unit. The agent’s drift is a 14.5-hour property; the joint context’s drift is a one-to-four-hour property depending on how active the session is.
The implication is that long-running autonomous agents need both a drift-eval loop (covered in the long-running post) and a session-handoff discipline (this post). The agent’s drift triggers an eval. The joint context’s drift triggers a reset. The two are not the same control loop and you cannot collapse them.
The session boundary is also a forking point. The long-running post names “fork, not restart” as a recovery shape; this post names the temporal handoff as the canonical fork mechanism. The four-field handoff artifact is the spec the fork starts from. The agent that runs for fourteen hours is not a continuous process. It is a chain of sessions held together by handoff artifacts.
The artifact is the operational unit. The session is the disposable carrier. The agent fleet that treats sessions as continuous bleeds attention; the fleet that treats them as disposable spends the cut deliberately and starts each new session at full attention.
FAQ
When should I start a new Claude Code session?
When two or more of five attention-budget signals fire: re-derivation loop, plan thrash, summary drift, tool-output amnesia, or decision regression. Token count is a weak proxy; behavioural signals are the strong cue. Practitioner measurement puts the quality cliff at roughly 50% context fill (MindStudio, 2026), well before auto-compact’s ~95% trigger (Morph, 2026). Reset at the behaviour change, not at the buffer warning.
How is session handoff different from subagent fan-out?
Different axes, different budgets. Fan-out spends tokens to expand parallel working memory; each subagent gets a fresh 200K window (Anthropic, 2026) at 4-7x parent-session cost. Session reset spends the attention budget; it cuts the parent’s saturated attention and starts a new one. Fan-out cannot fix parent-side attention saturation: subagent summaries return into the parent’s existing attention. Two moves, two ledgers; not substitutes.
Should I use /compact, /clear, or start a new terminal session?
/compact lossy-summarises and continues in the same process; useful when you trust the model to keep the right things and you want to avoid writing a handoff. /clear cuts cleanly while keeping the terminal session; useful when you have written your own handoff and do not want auto-summary. A fresh terminal session adds a re-read of CLAUDE.md and drops accumulated process state; cleanest cut. The four-field handoff artifact ports across all three (Claude.com, 2026).
What is the attention budget?
Anthropic’s term for the finite cognitive bandwidth a transformer applies to its context window (Anthropic, Sep 29 2025). Capacity (window size) is not quality (effective attention). RoPE-induced U-shaped attention costs 30%+ retrieval accuracy on mid-context information across 18 frontier models tested in 2025 (arxiv 2510.10276, 2025). Claude decays slowest. No frontier model is immune.
What goes in a session handoff document?
Four fields under 80 lines: decisions (settled choices with one-line rationale), open questions (with tie-break criteria), anti-goals (decisions explicitly rejected, to prevent regression), and next action (one concrete step). Community templates (jdhodges, mejba.me, who96) cover three of the four; anti-goals is the differentiator that prevents the new session from re-opening settled decisions.
What this changes about the next four-hour session
Three axes, three ledgers. The vertical handoff covers the action you would not have signed off on. The horizontal handoff covers the work you can parallelise. The temporal handoff covers the attention you have spent. The first two are documented and the field has shipping vocabulary for both. The third is the missing axis and the point of this post.
The next time a four-hour session feels heavy, do not reach for fan-out first. Run the five-trigger check against the transcript. If two or more fire, write the four-field handoff. Start a new session with the artifact pre-loaded. Spend the cut deliberately. The agent that runs your codebase is not a continuous process; it is a chain of sessions held together by artifacts. Treat the session as disposable and the artifact as load-bearing, and the next four hours start at full attention instead of the tail end of the last four.
If it was useful, pass it along.
