Tool Design for Agents: Schema Is the Prompt
When you give an LLM a tool, you hand it three strings: a name, a JSON schema, and a description. The model never sees your implementation. It never reads your test suite. It does not glance at your README. It reads those three strings on every turn, picks a tool, fills the arguments, and pays input tokens for the privilege. That makes the description a prompt. The schema is part of the prompt. The parameter names, the enum values, the required-vs-optional flags, the few-shot examples buried in the description, all of it goes into the same context as the user’s question and the prior tool results.
Most teams shipping MCP servers (or any function-calling surface) write descriptions like docstrings. Docstrings are for humans, and humans skim. LLMs do not skim. They weight every token, route on the weighting, and commit to a tool selection before they ever touch your code. A description that “looks fine” can still send an agent to the wrong tool half the time, because the prompt-shaped underspecification is invisible to the human reviewer and load-bearing to the model.
Three arxiv papers landed in February 2026 putting numbers on this. One scored 856 tools across 103 MCP servers and found 97.1% had at least one description smell, with 56% failing to state purpose. A second formalised smell-aware evaluation and measured the routing-accuracy cost: fixing a functionality smell improved tool-selection accuracy by 11.6 percentage points at p < 0.001; fixing an accuracy smell improved it by 8.8 points. A third showed misleading descriptions persistently reshape agent mental models across multiple turns. The fix is not “write clearer docs”. It is treating each description as a six-component micro-prompt with a token budget. This post lays out the rubric, runs the smell taxonomy, walks a real before/after rewrite from code-intelligence MCP v4, and explains why the June 15 Anthropic billing split turned every byte of description text into a metered line item.
Key Takeaways
- Tool descriptions function as prompts. The model reads name + JSON schema + free-text description on every turn and routes based on them. The implementation is invisible at selection time.
- 97.1% of public MCP tool descriptions have at least one smell, 56% fail to state purpose, 73% reuse names across the ecosystem (arxiv 2602.14878, Feb 2026). Fixing functionality smell improved tool-selection accuracy by 11.6 percentage points at p < 0.001 in a companion study (arxiv 2602.18914).
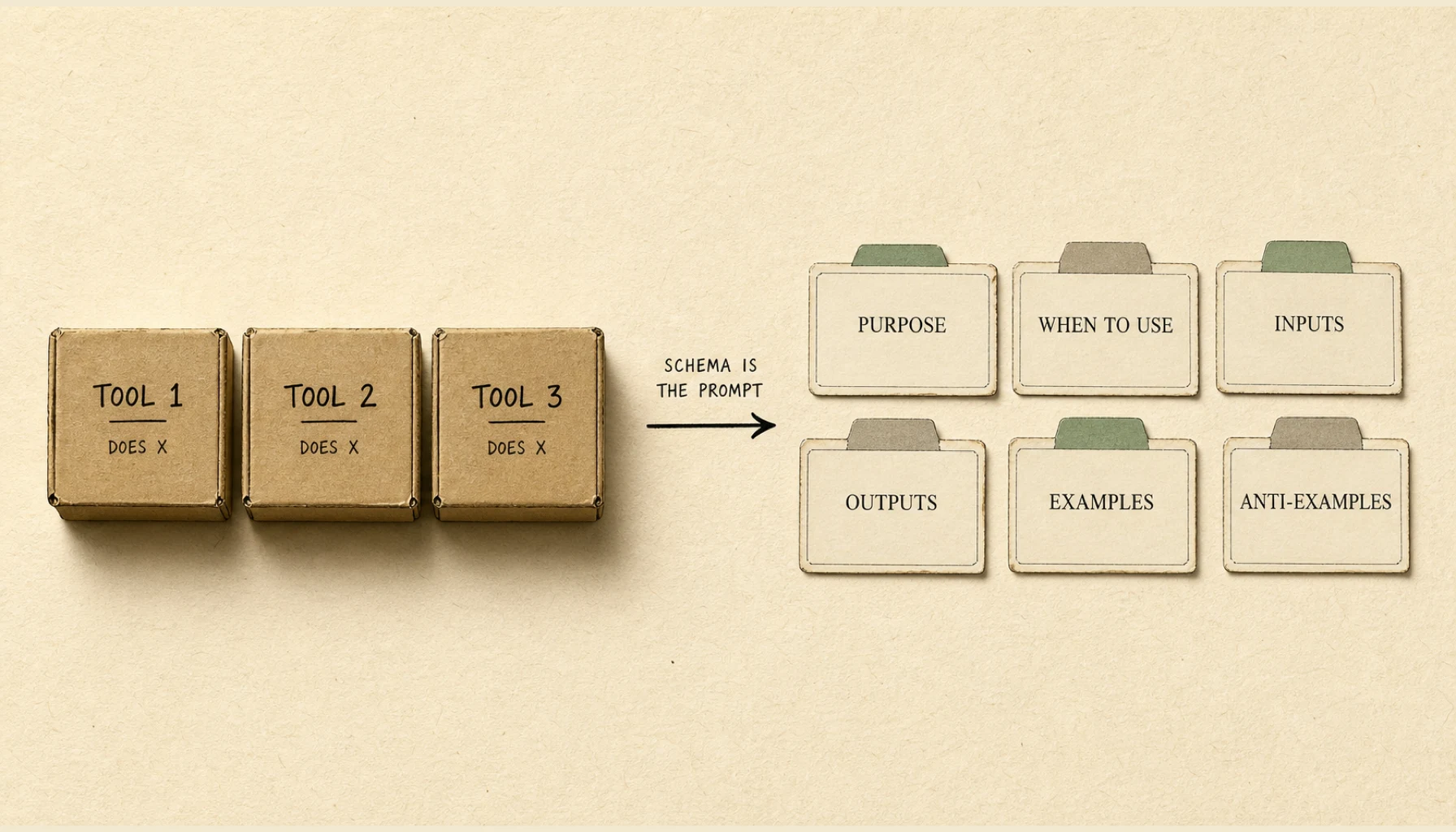
- A working description has six components in this order: purpose, when-to-use, inputs (semantic, not just typed), outputs, examples, anti-examples. Target 150 to 250 tokens per tool.
- The JSON schema is the prompt too. Parameter names, enums, required-vs-optional flags, defaults, and per-parameter descriptions all act as routing signal the model reads at selection time.
- On June 15 2026, Anthropic moved Agent SDK and
claude -ponto a separate credit metered at full API rates. A 17K-token tool-metadata payload now costs ~$0.05 per turn at Sonnet 4.6 and ~$0.09 at Opus 4.7, before any user prompt or tool result.- Description rewrites have order-of-magnitude effects on routing. Rewriting two tools in code-intelligence MCP v4 from one-sentence stubs to the six-component rubric cut the wrong-tool rate on graph-shaped questions from roughly 38% to single digits on a one-week Pylon sample.
What does the agent see when it picks a tool?
A coding agent picking a tool reads exactly three strings: the tool name, the JSON schema (parameters with types, requireds, and per-parameter descriptions), and the free-text tool description. The implementation is invisible. The unit tests are invisible. The repository README is invisible. By the time the agent calls your tool, it has already committed to a routing decision based on metadata alone, and it has paid input tokens for every byte of that metadata.
That metadata cost is not theoretical. Cloudflare’s first cut at an MCP server for its 2,500-endpoint public API would have consumed 1.17 million input tokens before the agent processed a user message; their two-tool Code Mode redesign got the same surface to roughly 1,000. Every one of those tokens was tool metadata, not code. The schema was the prompt. The redesign was a prompt rewrite at the protocol layer.
The implication runs deeper than “write shorter descriptions”. When an agent picks the wrong tool, the bug is rarely “the model is confused”. The bug is that the prompt-shaped description and schema underspecified the right answer. The model selected from what was on the page; what was on the page was insufficient. This reframes a class of agent failures from “tune the model” or “add more tools” into “rewrite the metadata as a prompt”. The arxiv smell papers are essentially prompt-engineering papers in disguise, and the people writing MCP servers are doing prompt engineering whether they realise it or not.
97% of MCP tool descriptions have at least one smell
A February 2026 paper titled “MCP Tool Descriptions Are Smelly!” empirically scored 856 tools spread across 103 public MCP servers and found that 97.1% of descriptions had at least one smell, with 56% failing to state their purpose clearly (arxiv 2602.14878). A companion paper covering broader MCP server documentation found that 73% of public MCP tools share names with at least one other tool elsewhere in the ecosystem, and that fixing functionality smell raised tool-selection accuracy by 11.6 percentage points at p < 0.001 (arxiv 2602.18914, Feb 2026). Accuracy smell, where the description and the code disagree, accounted for a further 8.8 percentage points at the same significance level.
The six smells the papers surface map cleanly onto missing or degraded description components. Each row of the table below names a smell, what triggers it, and (where measured) the routing-accuracy effect when the smell is fixed.
| Smell | What triggers it | Effect when fixed |
|---|---|---|
| Functionality | Purpose missing or vague (verbs like “look up”, “handle”, “manage”) | +11.6 pp tool-selection accuracy (p < 0.001) |
| Accuracy | Description and code disagree | +8.8 pp tool-selection accuracy (p < 0.001) |
| Calibration | Capability over-promised relative to implementation | Not separately quantified |
| Ambiguity | Two sibling tools’ descriptions overlap; routing is underdetermined | Not separately quantified |
| Underspecification | Parameter semantics, units, or required-vs-optional missing | Not separately quantified |
| Inconsistency | Parameter names, units, or return shapes drift across sibling tools | Not separately quantified |
Effect sizes from arxiv 2602.18914 (Feb 2026, 1,000+ tools sampled).
A third paper from the same window, “Don’t Believe Everything You Read” (arxiv 2602.03580), measured what happens when descriptions are actively misleading rather than merely smelly. Agents form persistent wrong mental models that survive multiple corrective turns. The cost is not just one wrong call; it is reasoning poisoning that contaminates the rest of the session. If a smelly description costs a routing point, a misleading description costs an entire trajectory.
What does a well-shaped tool description contain?
A well-shaped tool description has six components, in this order: purpose, when-to-use, inputs, outputs, examples, anti-examples. Each component pays back in routing accuracy more than it costs in tokens. Target a budget of 150 to 250 tokens per tool. Tighter than that drops a component; looser than that pads without raising accuracy, because the model’s attention does not weight redundant prose linearly.
Component by component, with target token counts:
- Purpose (one sentence, 15 to 25 tokens). State what the tool does, with concrete verbs and nouns. “Returns all functions and methods that call the given symbol.” Not “Looks up references.” Vague verbs hide the routing signal.
- When to use (one sentence, 15 to 25 tokens). Anchor the routing decision against sibling tools by name. “Use when the question is ‘who calls X’, ‘who references Y’, or ‘where is Z used’. Do not use for definition lookups (use
get_definition).” Naming the siblings is the single highest-impact change in most descriptions. - Inputs (per-parameter descriptions, 10 to 20 tokens each). Semantic, not typed.
symbol: the exact name of the function or method as it appears in source (case-sensitive, no parentheses).Not:symbol: string.The type system gives youstring; the model needs the semantics. - Outputs (one or two sentences, 25 to 40 tokens). Shape, units, sort order, and error cases. “Returns an array of call sites, each with
file,line,enclosing_symbol, andkind. Empty array if no callers found. Throws if symbol is not in the index.” - Examples (one or two examples, 30 to 60 tokens). Few-shot patterns the model can pattern-match against. One canonical positive case is usually enough.
- Anti-examples and when not to use (one sentence, 15 to 25 tokens). “Do not use to find variable assignments (use
trace_data_flow). Do not use to find subclasses (useget_type_graph).” Negative examples disambiguate from siblings the same way negative space defines a shape.
What the rubric implicitly cuts is just as important. Implementation notes, version history, links to external docs, prose paragraphs about design intent. Those belong in the README, not the description. Every kilobyte of description text rides on every turn, and the model is not reading your design rationale; it is routing on your verbs and nouns. Cut accordingly.
Is the JSON schema part of the prompt too?
Parameter names, types, enum values, required-vs-optional flags, and per-parameter description fields are all prompt tokens. They sit alongside the free-text description in the same model context, and the model reads them with the same weighting it gives the description prose. A parameter named q with description: "the query" carries strictly less routing signal than a parameter named symbol with description: "exact source-text name of the function, method, or class to find callers of". The schema is doing prompt engineering whether you wrote it that way or not.
Concrete schema-as-prompt patterns:
- Name parameters semantically.
symbolbeatsname;repository_pathbeatspath;commit_sha_or_branchbeatsref. The parameter name is the first thing the model sees when it considers how to fill the call. - Use enums where the answer space is small and known.
kind: "function" | "method" | "class" | "type" | "variable"beatskind: string. The enum acts as a hard constraint the model can read at selection time and a soft hint at fill time. - Add
descriptionto every parameter, not just the tool. The smell-evaluation paper found roughly seven in ten public MCP tools omit per-parameter descriptions entirely (arxiv 2602.18914). That is seven in ten tools where the model is guessing whatpathmeans. - Required-vs-optional carries routing signal. Marking
languageoptional with a sensible default tells the model “you can call this without it and you will get a reasonable answer”; marking it required without explanation forces the model to fabricate a value. - Default values are signal. A
budgetparameter withdefault: 200tells the model “you can omit this and you will get up to 200 results”; without a default the model spends reasoning tokens picking a number that may or may not be sensible for your tool.
The schema-as-prompt frame collapses the artificial line between “tool description” and “tool signature”. They are one prompt, served in two formats. The OpenAPI-shaped intuition that the schema is “just types and validation” misses the load-bearing role the schema plays at selection time. That same load-bearing role becomes a liability when the schema is attacker-controlled: a poisoned description steers the agent precisely because the model reads it as prompt, which is why a third-party tool is a supply-chain dependency, not a docstring.
A worked rewrite: code-intelligence MCP v4
When I rewrote the code-intelligence MCP from v3 to v4, every kept tool got a new description alongside the structural cuts already covered in stdio MCP doesn’t scale and the tool-shape redesign in building an MCP server for your codebase. The cuts and the rewrites were comparable in effort. Both were load-bearing for the wrong-tool rate, and skipping either one would have left the other underperforming.
Take find_references. The v3 description was a smelly one-liner: “Find references to a symbol. Useful for searching code.” Roughly fifteen tokens, every smell present. Purpose vague (“find references to a symbol” could mean references in comments, in source, in tests, in commits; the verb is undefined). When-to-use missing entirely. Outputs missing. Anti-examples missing. The sibling tool get_call_hierarchy had an overlapping description, and the agent picked between them by coin flip about 40% of the time on graph-shaped questions.
The v4 description follows the six-component rubric and sits at roughly 140 tokens:
Returns all callers and reference sites of a symbol across the repository. Use when the question is “who calls X”, “where is Y used”, or “what depends on Z”. Do not use for definition lookups (use
get_definition) or for subclass lookups (useget_type_graph). Inputs:symbol(exact case-sensitive name, no parens),kind(function | method | class | type | variable), optionalpath_prefixto scope to a directory. Returns an array of{file, line, enclosing_symbol, kind}sorted by file. Empty array if no callers found. Throws if symbol is not indexed.
Take predict_impact. The v3 description was five tokens: “Analyse impact of changes.” Smelly across the board, with a sibling collision against find_affected_code (which takes a diff and returns symbols; predict_impact takes a symbol and returns impact, the inverse). The v4 description sits at roughly 160 tokens and names the sibling explicitly:
Returns the predicted blast radius of changing a symbol: direct and transitive callers, tests covering the symbol, owners of affected modules, and recent commits touching nearby code. Use before refactors or before-merge reviews. Distinct from
find_affected_code(which takes a diff and returns symbols); this takes a symbol and returns impact. Inputs:symbol, optionaldepth(default 2). Returns{callers, tests, owners, recent_changes}. Returns empty fields where data is missing, not errors.
The headline number is the routing rate, but the second-order effect matters more. Per-session token usage fell even though per-tool description tokens roughly tenfold-ed. Retry loops collapse when the first tool call is the right one. The model stops second-guessing through sibling tools. The cache stops thrashing on grep-and-disambiguate. A 15-token description that misroutes the agent 38% of the time costs more total tokens than a 150-token description that misroutes it 9% of the time, and that is before you count the token cost of the wrong-tool results themselves.
How did June 15 change the economics?
Before June 15 2026, Claude Code subscriptions (Pro $20, Max 5x $100, Max 20x $200) absorbed Agent SDK and claude -p usage at roughly 15 to 30 times the equivalent API rate. Tool description bytes were effectively free overhead, padded inside the subscription envelope. From June 15, Anthropic moved Agent SDK, claude -p, Claude Code GitHub Actions, and third-party agents onto a separate monthly credit metered at full API rates with no rollover (Anthropic billing change, May 2026). Sonnet 4.6 input bills at $3 per million tokens; Opus 4.7 at $5. Every byte of tool description now ships on every turn at full retail.
A 17K-token tool-metadata payload (representative of a 30-tool API-mirror MCP server with smelly descriptions) now costs roughly $0.053 per turn at Sonnet 4.6 and $0.088 at Opus 4.7. A 200-turn agent session pays $10 to $18 just to read the tool list, before any user prompt or tool result. Multiply by seats, sessions, and developers, and the line item is material at a team level.
The mitigation is cache control. The Anthropic cache-control beta lets you mark the tool list as a cache breakpoint; a cache hit charges roughly 10% of the read cost, and the mechanics are covered end-to-end in cache-aware prompting. The wrinkle is that the cache evicts when the tool list changes. Volatile tool sets punish every change with a full refresh. Stable tool sets with disciplined descriptions get something close to the old subscription economics; volatile, churn-prone tool surfaces pay full retail every revision. The six-component rubric is partly a quality tool and partly a token-budget tool; predictable description size at predictable revision cadence is what cache control needs to actually work.
When are descriptions not the bottleneck?
Description quality is one of three independent variables in tool-selection accuracy. The other two are tool count (covered in building an MCP server for your codebase) and tool shape (covered in the project graph as the agent-shaped surface over a code index). Eighty tools with perfect descriptions still hit the routing cliff. Eight tools shaped wrong (verbs mapped to the wrong question shapes) cannot be saved by description rewrites. Order matters: cut to under twenty tools first, shape each tool around a real question the agent asks, then write the descriptions to the rubric, and finally tune cache control on top of stable metadata.
Skip the description work entirely if any of these hold: your agent uses one or two tools (filesystem MCP, single-purpose servers); your descriptions are auto-generated from typed source code with semantic doc comments already in place; your wrong-tool rate on real sessions is already under 5%. The diminishing returns get steep below that threshold. The two-line decision rule: if your agent picks the wrong tool more than 10% of the time on real sessions, descriptions are the cheapest fix. If your tool count is over 30, count is the bottleneck, and description work is premature optimisation.
Frequently asked questions
Are tool descriptions really prompts?
Yes. The model has no other channel to learn what a tool does. It reads the tool name plus JSON schema plus free-text description, picks one tool, and fills the arguments. The implementation is invisible at selection time. That makes the description and schema a prompt the model reads on every turn and pays input tokens for (arxiv 2602.14878, February 2026).
How long should a tool description be?
Target 150 to 250 tokens per tool covering the six components: purpose, when-to-use, inputs, outputs, examples, anti-examples. Shorter than 150 drops a component; longer than 250 wastes tokens without improving routing accuracy. The relationship between length and accuracy is non-monotonic; padding does not help (arxiv 2602.18914).
What is a tool description smell?
A pattern in a description that degrades agent tool selection. The Feb 2026 taxonomy names six: functionality (purpose missing or vague), accuracy (description disagrees with code), calibration (over-promised capability), ambiguity (sibling overlap), underspecification (parameter semantics missing), inconsistency (parameter names or shapes drift across siblings). 97.1% of 856 public MCP tools have at least one (arxiv 2602.14878).
Will the June 15 billing change make verbose descriptions too expensive?
For metered Agent SDK and claude -p workloads, yes. Every byte ships on every turn at full API rates ($3 per million Sonnet input; $5 Opus). The mitigation is cache control on a stable tool list, which charges roughly 10% of read cost on cache hits (cache-aware prompting). Volatile tool surfaces pay full retail; disciplined ones pay close to the old subscription rates.
What to do this week
Three takeaways. Tool descriptions are prompts, and the JSON schema is part of the prompt. The six-component rubric (purpose, when-to-use, inputs, outputs, examples, anti-examples) at 150 to 250 tokens per tool is the working target; it maps one-to-one onto the February 2026 smell taxonomy and onto the second-order effects the smell-evaluation paper measured. The June 15 billing split turned tool descriptions from free subscription overhead into a metered line item, which makes description discipline a budget tool as much as a quality tool.
Before the next sprint, pick the tool in your MCP server with the highest wrong-tool rate and rewrite the description to the six-component rubric. Measure the rate again over a week. If you do not have a wrong-tool rate metric yet, instrumenting one is the first move; everything downstream depends on it. The companion posts on tool shape, the project graph abstraction, and cache-aware prompting cover the adjacent variables; together they form the four-variable system (count, shape, description, cache) that determines how much your agent pays to pick a tool, and how often it picks the right one.
If it was useful, pass it along.
