Stdio MCP Doesn't Scale: Dropping 3,662 Lines for a Daemon
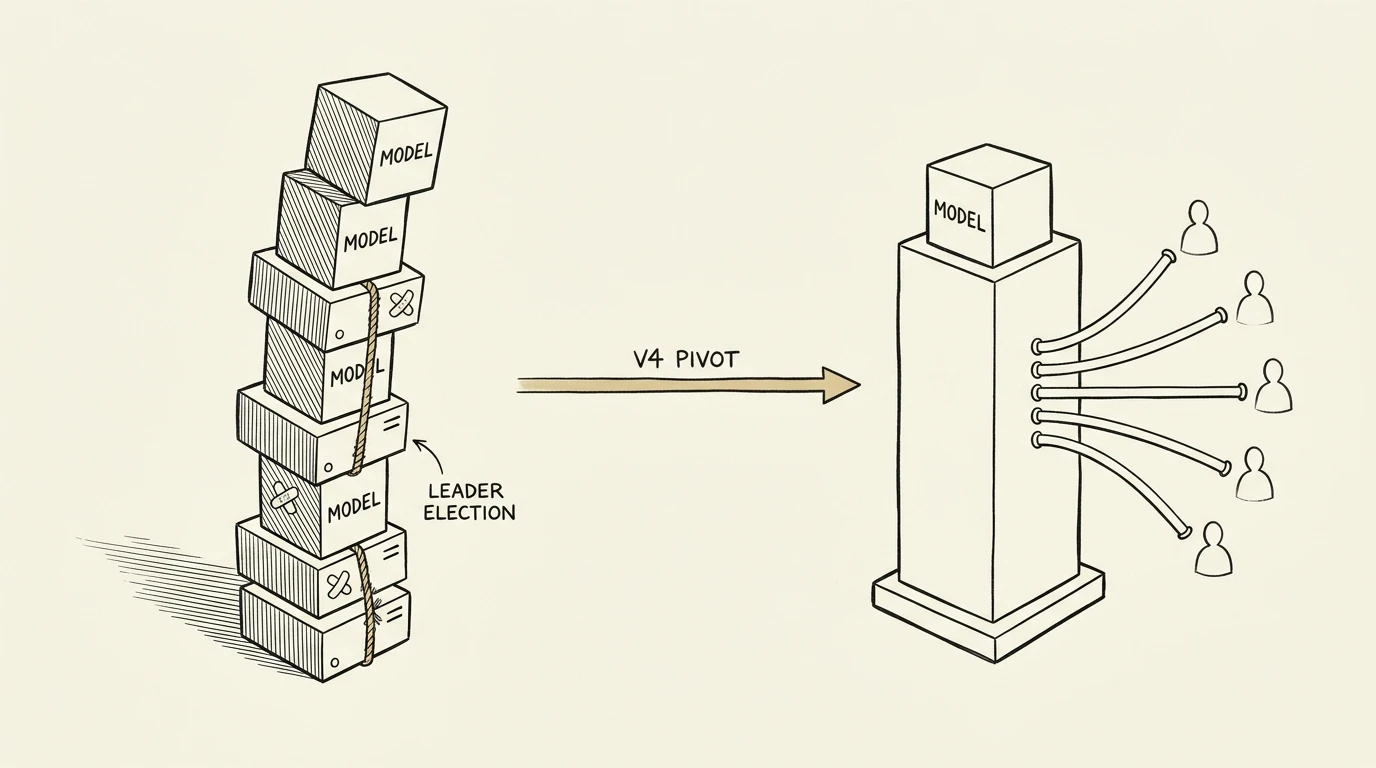
Five Claude Code subagents fan out to review a PR. Each one carries its own MCP server config. Each one spawns its own stdio code-intelligence subprocess. Each subprocess runs the per-repo leader-election handshake, loads what it has to load, and sits there until the chat session ends. Then the chat ends, every subprocess takes SIGTERM, and the next chat spins the whole tree up again from cold cache. Multiply by three repos and by whichever subagents had spawned their own subagents that day, and the process tree got genuinely embarrassing.
This is the failure mode this post is about. Per-instance steady state was not the bottleneck. Leader election kept the description LLM loaded only on the elected leader, per-repo flock serialised index writes, and a heartbeat file handled crashed leaders cleanly. Memory and lock contention were tolerable in isolation. What stdio gave us no surface for was lifecycle: no way for those mitigations to outlive a chat session, no way to stop subagents from spawning their own copies of the server, no way to amortise per-spawn cost across a working day. The mitigations were getting expensive to maintain, and the management overhead was compounding faster than we could refactor.
v4.0.0 of my code-intelligence-mcp-server, released today, deletes the stdio path entirely. 3,662 lines down, 69 up, 838 tests still pass. The architecture is one launchd-managed daemon that outlives chat sessions, accepts HTTP from any number of subagents on the same machine, and never pays cold start a second time. Here is the lifecycle cost stdio could not fix, the workaround layer that kept it usable, and the signals that mean your MCP server is next.
Key Takeaways
- Stdio MCP gives one subprocess per client and dies with the chat session. Workarounds (per-repo leader election with
flock, leader-only description LLM loading, follower processes that share the Tantivy reader) keep the steady-state cost bounded, but they cannot outlive a chat session, cannot stop subagents from spawning their own subprocesses, and cannot amortise cold-start across a working day. Every new chat = new process tree, new model load, new index reader bootstrap.- Leader election is the load-bearing workaround. 430 lines (
src/leader.rs) shipped on 2026-02-14 (d1b6a38) bounded the per-instance cost by gating the description LLM and index writes to the elected leader, and the v4 pivot deleted all of it (4736a0d, 2026-05-16) once the lifecycle problem made the maintenance unjustifiable.- The MCP
rootscapability is the standard way to tell a server “this is the workspace you should index.” A survey of 7 popular MCP clients found 1 implemented it correctly; the rest either omit the capability or advertise it and returnMethod not foundon the actual call (MCP spec, 2025).- GitHub’s Copilot team measured a 400 ms response-latency reduction and a 2-5 percentage-point SWE-Lancer accuracy gain after cutting tool count from 40 to 13 (GitHub Engineering, 2026); the equivalent on the transport layer is to stop paying per-subprocess overhead at all.
- 93% of remote MCP servers analysed in a February 2026 scan of 1,400 servers run on Streamable HTTP, the same transport this server pivoted to (bloomberry, 2026). The market has already voted; stdio is the legacy path.
Where does the stdio MCP tax compound?
Stdio MCP is a per-client subprocess. Open Claude Code, the editor spawns an MCP server. Open a second instance, a second subprocess. Spawn three subagents, three more subprocesses. Run a PR-review pipeline that fans out to five reviewers, five more. End the chat, the editor sends SIGTERM down the tree, every subprocess exits, and the next chat starts from cold. The default sample MCP server in the official SDK launches with a few megabytes of resident memory, so the per-subprocess cost feels invisible. That intuition does not survive contact with any server that loads models, holds an index in memory, or watches files, and it does not survive at all once you start counting the cost per chat session.
The code-intelligence server holds three model artefacts in resident memory once the indexing pass is complete. The current footprint is roughly 1.5 GB for jina-code-embeddings-1.5b (Q8_0), 600 MB for the BGE reranker, and 1.0 GB for the Qwen2.5-Coder-1.5B description LLM during the indexing pass (freed afterwards). First-launch model download is ~3.2 GB. Under stdio with leader election active, the elected leader paid all of that; each follower paid the embedding cost (~1.5 GB) plus a Tantivy reader handle and a file-watcher thread. The leader-election layer bounded the LLM duplication at one per repo, and that single decision is what kept the in-isolation memory cost tolerable for as long as it was.
The numbers held up across two README revisions. In February 2026, when the embedding model was a ~500 MB ONNX runtime variant, the project README quantified five-to-six stdio clients on a single repo at roughly 3.6 GB resident, versus 1.2 GB for the opt-in standalone HTTP mode that the server already supported as an escape hatch. By the v4 pivot, the embedding model had moved to a llama.cpp Metal GGUF at ~1.5 GB, so per-follower cost had effectively tripled while the leader-only LLM stayed bounded. The cross-repo example in the most recent README is the cleanest single figure: five client instances spread across three repos load five copies of the embedding model, ~2.6 GB of duplicated weights, before any indexing pass starts. That is steady-state only. The chat-session multiplier (every session pays the cold start again) does not appear in that number at all.
The chart is steady-state and understates the working-day cost in two ways. Chat sessions are the first multiplier: every chat ends with SIGTERM to the whole subprocess tree, and the next chat reloads every model, runs every leader-election round, rewarms every Tantivy reader. Twenty chats with subagent fanout pays cold start dozens of times. Cascade spawning is the second: a subagent that has its own MCP config starts its own stdio subprocesses, and stdio gives the parent no way to say “use the server I already started.”
Even servers that ship without on-device models still pay for the same parser, the same Tantivy reader, the same file-watcher thread, and the same RPC handler loop per subprocess. The model line is what makes the cost visible on a laptop; the structural problem is that stdio gives you no surface to share anything across clients or across sessions.
Citation capsule: Stdio MCP allocates one subprocess per client by spec, and the subprocess lifecycle is bound to the client’s chat session. The code-intelligence server’s model footprint is ~1.5 GB embedding plus ~1.0 GB description LLM during indexing (SYSTEM_ARCHITECTURE.md, v4.0.0). Under leader election, five clients on one repo run as one leader (~2.5 GB) plus four followers (~1.5 GB each) for ~8.5 GB steady state; five across three repos run three leaders plus duplicated embeddings for ~15 GB. The steady-state number understates the working-day cost because every chat session pays the cold start again.
Why didn’t leader election fix it?
The stdio days had one obvious defence against the cost: pick one. In February 2026 I added per-repo leader election (commit d1b6a38). Each stdio subprocess took an exclusive flock() on a per-repo state file. The first one in became the leader and ran the index writes, the file watcher, and the description-LLM passes. Followers ran read-only, reloaded the Tantivy reader on an interval, and exposed an instance_role field through get_index_stats so consumers could see the topology. A heartbeat file plus stale-detection plus auto-promotion handled crashed leaders. It was 430 lines of careful logic and it did its job.
Leader election fixed the things it set out to fix. Per-repo write correctness held when five clients raced for the same Tantivy index, the description LLM stopped duplicating across followers, and the file watcher only ran where it could act. The in-isolation memory line in the previous section is the line leader election bought; without it the same scenario would have been substantially worse.
What it could not do was anything about lifecycle. The leader-election state lived inside the subprocess; when the chat session ended and SIGTERM ran down the tree, the elected leader died with everything else, and the next chat re-ran the whole flock dance from cold cache. It could not stop a subagent that carried its own MCP config from spawning its own subprocess and joining the election round as a new follower. It could not amortise model load across the working day, because the working day was made of dozens of independent chat sessions whose subprocess trees did not share state.
The maintenance arc was the second half of the story. The 2026-03-29 architecture review flagged the dual-mode bootstrap as smell S8, “duplicate embedder creation, config parsing, and service wiring across run_embedded() and run_standalone(),” and as “low priority.” That priority was right at the time and wrong six weeks later. Every feature, every bugfix, and every test had to land in two code paths; the stdio test surface alone was 1,961 lines (integration_index_search.rs plus integration_mcp_tools.rs) of behaviour the daemon path would never need. The leader-election layer doubled it again: a heartbeat-staleness regression on the follower side was real engineering work even when the daemon path was already working.
The structural fix is the simple one. A daemon does not need leader election because there is only ever one writer. It outlives chat sessions, so cold start is paid once at boot. The followers become HTTP clients of the same in-memory state, so subagents stop spawning subprocess trees of their own. The 430 lines of leader code disappeared because the problem they solved disappeared, and the lifecycle problem they could not solve disappeared with the transport that created it.
Citation capsule: Leader election is the load-bearing workaround for any per-process MCP transport. It bounds the per-instance cost (one LLM per repo, one writer per repo, one file watcher per repo) but does not address lifecycle: the elected leader dies with its chat session, subagents with their own MCP config still spawn their own subprocess trees, and the cold-start cost is paid once per session not once per machine. The code-intelligence server carried 430 lines of leader logic plus 1,961 lines of stdio integration tests across two test files; the v4 pivot deleted all of it in commit
4736a0dbecause the daemon transport made both the per-instance bound and the lifecycle problem moot at the same time.
Why was MCP roots the killer?
The transport cost is the boring half of the story. The reason stdio became indefensible was that the standard mechanism for telling an MCP server “this is the workspace you should index” turned out not to work in practice.
The MCP specification defines a roots capability. Clients advertise roots at initialize, the server calls roots/list, and the client returns one or more URI roots that scope the server’s work. On paper, this is exactly what a workspace-bound code intelligence server needs. In practice, the audit I ran against seven popular MCP clients before the v4 pivot returned a single passing result. Claude Code implements roots correctly. The rest either omit the capability, advertise it and then reject the call, or advertise it and silently disconnect.
The two reproducible failure cases are the headline. Cursor advertises roots in its initialize response and returns Method not found on roots/list. The bug is forum-confirmed, has been open for eight months, and is the reason a forum thread of users explains the workaround with environment variables. OpenCode connected to the daemon test harness, never responded to roots/list, and disconnected after 12 seconds with no error. The other clients I checked either lacked the capability entirely or sent malformed payloads.
A workspace-bound server that depends on roots does not have one bug to chase per client; it has a fragility per client. Worse, the natural stdio workaround (a BASE_DIR environment variable set by the client at spawn time) does not work cleanly for subagents, because the parent client owns the spawn and the subagent has no way to override the workspace. In multi-project workflows, this produces silent miss-targeting: a subagent thinks it is querying repo A and is actually querying repo B because the env vars came from the parent’s MCP-server config.
The only practical fix is an out-of-band binding mechanism that the server controls. A query parameter on the transport URL is the simplest possible form. v4 binds the workspace via ?repo=<absolute path> on the proxy’s HTTP URL, captures the mcp-session-id issued by the rust-mcp-sdk at the same hop, and pins the pair for the rest of the session. roots/list becomes a fallback (Claude Code only). bind_workspace exists as an explicit tool call for manual escape, and a single-repo registry fallback handles servers that only ever serve one repo. The binding hierarchy is four sources, first match wins, and the first source is the one the user controls directly.
This single change is the largest reason the migration was worth it. A daemon exposes a URL, and a URL can carry parameters; a stdio subprocess exposes a pipe, and a pipe cannot. The transport rewrite was a cost reduction; the binding rewrite was a correctness fix.
Citation capsule: A survey of 7 popular MCP clients before the v4 pivot found 1 (Claude Code) correctly implementing
roots; Cursor returnsMethod not foundonroots/listdespite advertising the capability, and OpenCode disconnects after 12 seconds. Stdio transports cannot expose out-of-band binding because a pipe has no URL; the v4 daemon binds via?repo=query parameter, pinned to the SDK-issuedmcp-session-idat the proxy hop. The 4-source binding hierarchy (query,roots/list,bind_workspacetool, registry fallback) closes the correctness gap stdio left open.
What dropped when stdio dropped?
The v4.0.0 pivot landed in three commits on 2026-05-16 and shipped the next day. The headline diff on commit 4736a0d is “refactor(v4)!: drop stdio embedded mode and leader election.” 3,662 lines deleted, 69 added, 838 tests passing afterwards. The deletions are worth itemising because they make the maintenance cost concrete.
The new architecture is one process. A single launchd-managed binary owns four ports on 127.0.0.1. Port 17800 is the public MCP proxy: an axum server that captures the ?repo= query parameter, pairs it with the mcp-session-id from the rust-mcp-sdk on the first request, and forwards everything to the upstream MCP handler. Port 17801 serves a /.well-known/mcp discovery document. Port 17802 is the JSON API and an embedded dashboard with an SSE log stream. Port 17900 is the internal Streamable HTTP listener that the rust-mcp-sdk drives. All four ports bind 127.0.0.1 only and reject non-localhost Origin headers as a DNS-rebinding defence.
The handler is StandaloneHandler, ~700 lines in src/server/standalone.rs. It owns a lazy per-repo AppState: the first request for a given repo path bootstraps the embedder, the indexer, the description-LLM (if enabled), and the Tantivy reader once, and every subsequent request from any client reuses the same in-memory state. Subagents are HTTP clients of the same daemon, not subprocesses of their own MCP servers. They share one machine and one trust domain, so they coordinate in-process; MCP is the tool layer, and agent-to-agent coordination is a separate layer above it. The cost compounding the previous section described disappears not because the models got smaller but because there is one process holding them.
The JSON API and dashboard exist because the daemon is observable. A long-lived process can stream logs, expose job status, and surface a Jobs panel for in-flight reindex work; a stdio subprocess that lives for the length of one editor session cannot. The dashboard, the per-repo activity indicator added in v4.0.3, and the transparent -32016 session-recovery the proxy added in v4.0.1 are all features the daemon transport made possible, in the same way that Claude Code’s hook lifecycle makes deterministic gating possible by giving you a stable surface to fire on.
Citation capsule: The v4 daemon is a single launchd-managed binary on four 127.0.0.1 ports: 17800 public MCP proxy (axum), 17801 discovery, 17802 JSON API plus dashboard plus SSE log stream, 17900 internal rust-mcp-sdk listener.
StandaloneHandlerholds a lazy per-repoAppState; the first request bootstraps the embedder, indexer, and Tantivy reader, and every subsequent request reuses the in-memory state. 838 tests cover the daemon path; the entire stdio test surface was deleted alongside the stdio code.
How did the migration land for users?
The transport change had to be invisible to anyone configuring the server through Claude Code’s standard mcpServers block. The v4 release does three things to make that work.
The npm package becomes a thin shim that resolves the daemon binary in three steps: CODE_INTELLIGENCE_MCP_BINARY if set, the Homebrew-installed binary on PATH, and a GitHub Releases fallback. It deliberately does not inject the v3-era environment defaults (BASE_DIR, EMBEDDINGS_BACKEND); the daemon ignores them and overriding would mask real configuration issues. The CLI accepts --standalone as a silent no-op for one release with a deprecation warning, so existing configs keep working.
A migrate subcommand rewrites ~/.claude.json in place. It backs the file up to ~/.claude.json.bak.<unix-ts> (keeping the last three backups), iterates every command: npx ... entry across mcpServers, projects.*.mcpServers, and projects.*.enabledMcpjsonServers, and points each at the new wrapper. install, uninstall, start, stop, and status manage the launchd plist. The combined effect: a returning user runs code-intelligence-mcp migrate once and is on the daemon.
The old @iceinvein/code-intelligence-mcp-standalone package is deprecated; its README is now a migration table and the package will be unpublished after v4.0 stabilises. I did break one thing on purpose: instance_role disappeared from get_index_stats because the concept of a leader and a follower no longer exists. Default port moved 3333 → 17800; URL binding (?repo=) replaces BASE_DIR. These are the only intentional breaks; everything else either keeps working or warns once and keeps working.
The deprecation arc matches the pattern from the promotion ladder: the legacy surface stays until the new surface has demonstrated stability, then gets explicit deprecation flags, then gets removed in a major version. The warning stage is what makes a major version feel routine.
Citation capsule: The v4 npm package is a thin wrapper that locates and execs the daemon binary; the
migratesubcommand rewrites~/.claude.jsonin place with three rotating backups.--standalonebecomes a silent no-op for one release with deprecation warning. The deprecated@iceinvein/code-intelligence-mcp-standalonepackage (the v3 standalone-mode shim) will be unpublished after v4.0 stabilises. The default port changed 3333 to 17800; theBASE_DIRenv var was replaced by?repo=URL binding;instance_rolewas removed fromget_index_stats.
When does stdio MCP still make sense?
The v4 pivot is not an argument that no MCP server should use stdio. It is the right transport for a real set of cases.
Stdio works when the server is single-client by construction: a linting MCP server scoped to one editor session, a one-shot conversion tool, a single-user developer utility. The transport cost is the cost; there is no second client to multiply it. Stdio works when the per-process footprint is genuinely small: ten thin wrappers over a CLI tool, no state above getpid(), spawn cheap, exit fast, accumulate nothing. And stdio works when the security model demands process isolation: a server that performs sensitive operations (signing, key access, payment) may want exactly the per-client subprocess boundary that stdio provides.
Stdio does not work when any of three signals fire: the server loads models, holds an index, or watches files. Any one puts the per-subprocess footprint above what is reasonable to multiply by client count. Two together put it past the threshold where the cost is invisible. For my server, all three fired. The code intelligence post walks the workload; the moment that workload runs in more than one editor session at a time, the transport choice has to change.
Citation capsule: Stdio is the right MCP transport when the server is single-client by construction, holds no shared state worth sharing, or requires process isolation as a security property. It is the wrong transport when the server loads models, holds an index, or watches files, because each subprocess pays the full cost and there is no surface to share state across clients. The decision variable is workload, not maturity; the code intelligence post describes the workload that forced the switch.
How do I know my MCP server needs this jump?
Five concrete signals; if two or more fire on your server, the migration is deferred maintenance, not a question of taste.
Model-load: the server holds ML weights or any artefact above ~100 MB resident after initialize. Multiply by realistic client count (editor + agents + reviewers + CI) and ask whether the result is acceptable on a developer laptop. For the code-intelligence server, the number crossed 8 GB at five clients with leader election active.
Index-cost: the server bootstraps an index in more than a few seconds. Every stdio subprocess pays that bootstrap; if the index is shared across clients in practice, you pay once per process for the same result. A daemon pays it once at boot.
File-watcher: the server installs notify/fswatch/fsnotify handlers. Multiple subprocesses on the same paths produce redundant events and, on macOS, occasional event drops under contention.
Roots-binding: the server is workspace-scoped and depends on the MCP roots capability. The audit your users care about is the audit on the clients they actually run. If even one fails roots/list in a way you cannot work around with env vars, a URL-bindable transport solves the class of problem that workaround postpones.
Observability: you want a dashboard, an SSE log stream, a jobs view, or any other surface with a lifetime longer than one client session. Stdio cannot give you that because the process exits with the client.
The MCP server design framework covers the tool-shape side; this post is the transport-layer side. Both matter; either alone is half the answer.
Citation capsule: Five concrete signals that an MCP server needs to move off stdio: model-load above ~100 MB per subprocess, index bootstrap above a few seconds, file-watcher contention across processes,
rootscapability gaps in real clients, or any observability surface with a lifetime longer than one client session. Two or more firing means the transport is the bottleneck. The MCP server design framework covers the tool-shape complement to this transport-layer post.
FAQ
What is the actual difference between stdio MCP and Streamable HTTP MCP?
Stdio MCP is a per-client subprocess that exchanges JSON-RPC over the subprocess’s stdin/stdout pipes. The client owns the subprocess lifecycle. Streamable HTTP MCP is a long-lived HTTP server that handles MCP framing over a single endpoint, with session IDs in HTTP headers and optional SSE for server-initiated messages. The bloomberry survey of 1,400 remote MCP servers in February 2026 found 93% on Streamable HTTP (bloomberry, 2026); the market has already voted. The relevant difference for any server with shared state is that one process can own the state across all clients, instead of paying for it per client.
Why not just keep stdio as an option and let users pick?
That was the v3 design and it became the maintenance debt that motivated v4. Six weeks after the architecture review filed dual-mode bootstrap as smell S8, the cost of carrying two transports through every feature, every bugfix, and every test passed the cost of cutting one. The deletion is 3,662 lines in commit 4736a0d. A single transport is cheaper to maintain than a dual transport even when the second is technically simpler.
How do you keep the daemon secure if it is an HTTP server?
All four ports bind 127.0.0.1 only, never 0.0.0.0. The proxy rejects any non-localhost Origin header as a DNS-rebinding defence. There is no remote attack surface unless the user explicitly tunnels a port. The /.well-known/mcp discovery document and the dashboard SSE stream are localhost-only as well.
What happens if a user is mid-conversation when the daemon restarts?
v4.0.1 added transparent -32016 session recovery in the proxy. When the upstream returns the spec-defined session-expired error, the proxy re-initialises a session and replays the original request once. The client sees a slightly slower response on that one call; no user-visible error. Repeated recovery within a short window surfaces as an explicit error so misconfigured clients are not silently retried indefinitely.
Conclusion
Stdio MCP was the default transport, the easiest one to ship, and the right answer for a real and shrinking set of cases. It collapses the moment a server loads models, holds an index, or watches files, and runs in more than one client at a time. Leader election bounded the steady-state cost but could not address lifecycle: the elected leader died with its chat session, subagents with their own MCP config still spawned their own subprocess trees, and cold-start was paid per session. The roots capability gap in real clients made the natural stdio workaround (env-var workspace binding) silently fragile in multi-project workflows. The v4.0.0 pivot deleted the stdio path entirely: 3,662 lines down, 838 tests still passing, one launchd-managed daemon on four 127.0.0.1 ports, workspace binding via ?repo= URL parameter pinned to the SDK-issued session ID. The market has already voted; 93% of remote MCP servers run Streamable HTTP (bloomberry, 2026).
Run the five-signal checklist against your own MCP server this week. Two or more firing means the migration is deferred maintenance, not a question of taste. The MCP server design framework covers the tool-shape side; this post covers the transport-layer side; the code intelligence workload is the case study they bracket. Build the transport that fits the workload; let the workload tell you when to move.
If it was useful, pass it along.
