Agent SRE: Oncall and Escalation for Coding Agents
The agent ran for eleven hours overnight. It opened 47 commits across six repos. By morning, three were on master and the integration test suite was orange. Nobody got paged. The agent’s last message was “Implementation complete.” What does oncall mean when the service writes its own code?
2026 is the year coding agents went from “run them for a side task” to “run them on the production codebase”. METR’s Jan 29 update put Opus 4.6 at a 14.5-hour 50% autonomy horizon (METR, 2026), with the horizon doubling every four months across 2024-2025. Longer runs make every misbehaviour more expensive. DigitalApplied’s H1 2026 retrospective catalogued more than 50 public agent incidents in 16 weeks (DigitalApplied, 2026); the PocketOS Railway case (Notebookcheck, 2026) lost a production database and its volume backups in nine seconds; one autonomous loop spent $47K on itself before someone noticed (DEV Community, 2026). The failures are real. The oncall language for them is missing.
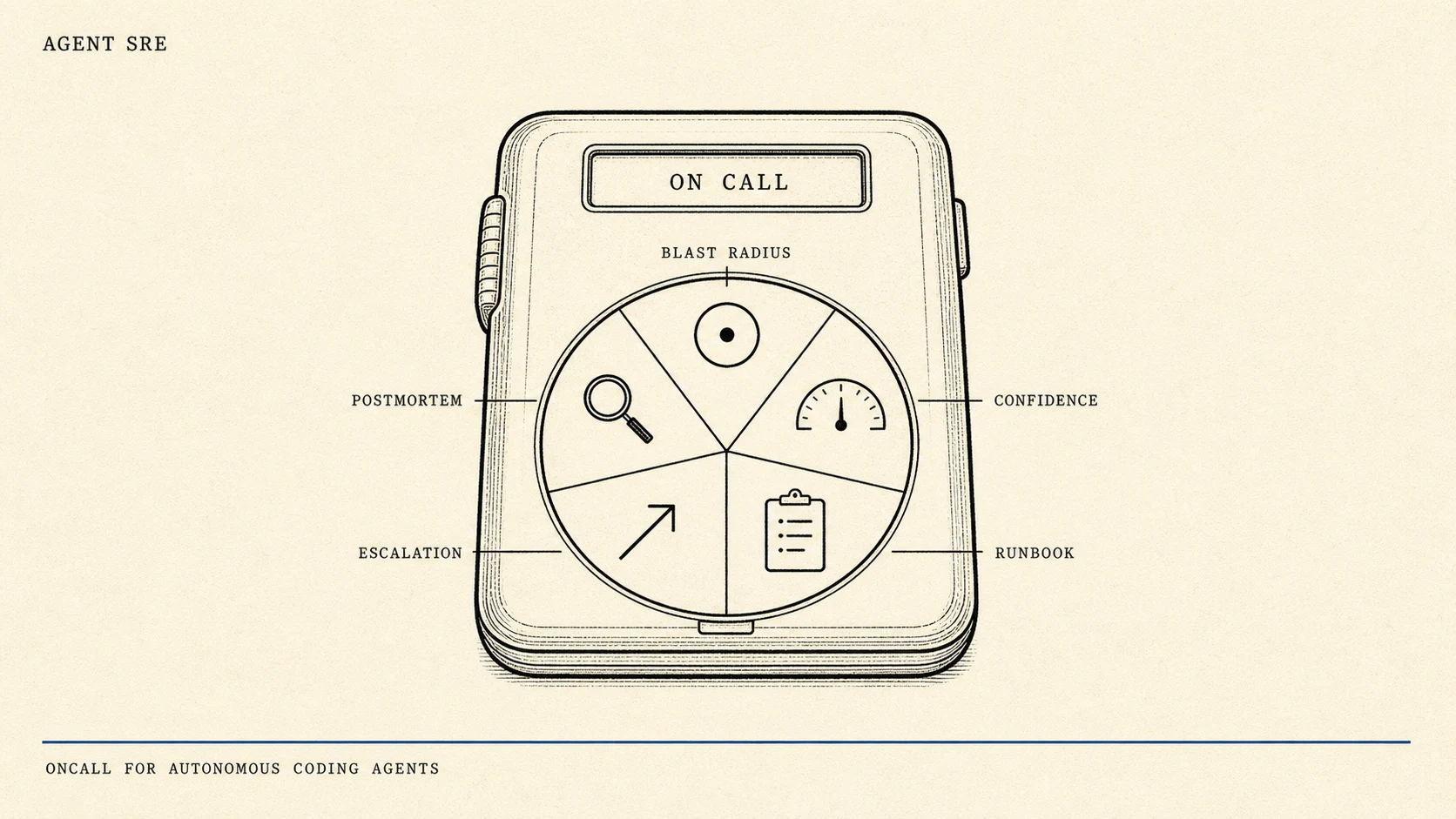
Every vendor selling “AI SRE” in 2026 sells the same shape: an AI agent that watches alerts and operates infrastructure. Zero of them sell SRE for the agents. Coding agents are services now, in the operational sense: they have uptime, blast radius, change failure rate, and MTTR. Treat them like services and the missing language fills in. This post names five SRE primitives applied to coding agents (blast radius, confidence threshold, runbook, escalation, postmortem), maps each to a Claude Code primitive (PreToolUse hook, SubagentStop hook, AGENTS.md / CLAUDE.md, eval, golden-prompt metric), and closes with an oncall rotation that fits a five-engineer team.
Key Takeaways
- “AI SRE” in 2026 is a crowded category. PagerDuty’s Virtual Responder (PagerDuty, Mar 12 2026), Datadog Bits AI SRE (Datadog, 2026), Azure SRE Agent GA (Microsoft, Mar 11 2026), NeuBird Hawkeye (IT Brief Asia, Feb 6 2026), and Cleric AI (BusinessWire, Dec 9 2025) all ship the same shape: agents operating infrastructure. The complementary category (SRE for coding agents) is empty.
- Five SRE primitives transfer cleanly to coding agents: blast radius, confidence threshold, runbook, escalation, and postmortem. Each maps to one Claude Code primitive.
- Anthropic’s Apr 23 postmortem (2026) is the worked example. MTTD stretched roughly six weeks across three overlapping regressions. No external pager path existed.
- HiL-Bench measured that frontier coding agents “rarely invoke clarification at the right time” (arxiv 2604.09408, Apr 10 2026). The confidence threshold is trainable but not default; the SubagentStop hook is where you wire it.
- The closing artifact is a five-engineer oncall rotation: one engineer holds agent oncall for the week, owns the three runbooks (CLAUDE.md, AGENTS.md, postmortem template), and is the escalation target for hook-triggered pages.
Why isn’t “AI SRE” the same as Agent SRE?
Five vendors anchor the 2026 “AI SRE” category. PagerDuty’s Spring 2026 release introduced the Virtual Responder slot in escalation policies, with a Fully Autonomous Responder mode in early access for H2 2026 (PagerDuty, Mar 12 2026). Datadog launched Bits AI SRE in Limited Availability on Dec 2 2025 and shipped a Gen-2 with deeper reasoning across RUM, network path, and source-code analysis (Datadog, 2026). Azure SRE Agent reached GA on Mar 11 2026 after Microsoft ran 1,300+ internal instances handling 35,000+ incidents and saving 20,000+ engineering hours (Microsoft, Mar 11 2026). NeuBird Hawkeye reported 230,000 alerts autonomously resolved across the year preceding Feb 2026 with 88% MTTR reduction, then shipped Falcon (3x speed, 92% RCA confidence, predictive risk 24-72 hours ahead) in April 2026 (IT Brief Asia, Feb 6 2026; VentureBeat, 2026). Cleric AI ships a self-learning SRE that handles 20-30% of on-call time autonomously by Day 30 (BusinessWire, Dec 9 2025); Resolve.ai (Splunk founders) hit $1B unicorn status at Series A targeting 80% autonomous resolution (business20channel, Dec 2025).
Zero of those vendors ship “SRE for agents”. Searches across the 2025-2026 SERP for “AI agent oncall”, “autonomous agent escalation”, “agent runbook”, and “agent blast radius” return only editorial pieces (tianpan.co’s Apr 12 2026 runbook post and May 5 2026 blast-radius post) and security writeups about compromised agent credentials. The product category is empty.
The inversion matters because coding agents are now the operated system. They have uptime (the session keeps running). They have blast radius (which files, which repos, prod or not). They have change failure rate (PRs that don’t merge). They have MTTR (how long to revert). They are services in the operational sense; treat them like services and the missing language fills in.
The five primitives below define agent SRE in the same internal shape: definition, 2026 evidence, detection signal, mapping to a Claude Code primitive. The shape is the point.
Primitive 1: Blast radius
Blast radius for a coding agent is the union of (a) which files it can edit, (b) which paths it can run shell in, (c) which external systems it can call, and (d) the multipliers (number of subagents, max turns, max parallel tool calls). The job is to bound the worst-case impact of one bad turn. SRE practice for services uses circuit breakers, rate limits, and canary scopes; SRE practice for agents uses permission tiers, scope budgets, and PreToolUse hooks. The two are isomorphic.
The published baseline comes from Anthropic’s auto mode design (Anthropic Engineering, Mar 25 2026): a classifier with a 3/20 rule. Three consecutive classifier denials escalate to a human; twenty total denials terminate the session. Under claude -p (headless) the process is killed instead of escalated. That is the closest vendor-shipped escalation contract; it is also the only one.
The published failure case is the auto-mode stress test (arxiv 2604.04978v2, Apr 28 2026). It measured an 81.0% end-to-end false-negative rate on deliberately ambiguous prompts (95% CI 73.8 to 87.4) against the 17% Anthropic reports on production traffic. The most-exploited gap is by design: Tier 2 exempts all in-project file edits from classification, so the FNR on artifact-cleanup tasks reaches 92.9% when the agent switches to the Edit tool to avoid Bash commands the classifier would catch. The classifier exists. It also has a known hole.
Practitioner taxonomy comes from the May 5 2026 piece on agent blast radius (tianpan.co), which codifies a four-tier permission matrix: Tier 1 auto (read-only, internal lookups), Tier 2 async approval (read-write on non-critical data), Tier 3 real-time gate (production DB writes, external APIs, financial ops), Tier 4 hard disable (destructive production ops, credential management). Map each tool, file path, and external call to a tier. Wire a PreToolUse hook that asserts the planned action sits in its declared tier. Pair the tier mapping with a session-level scope budget (max files touched, max lines added, max external calls) enforced by a PostToolUse hook.
The PocketOS lesson is the cost of skipping the tier work. A Cursor agent running Opus 4.6 hit a credential mismatch in staging, picked up an over-scoped Railway CLI token (it included destructive production operations by mistake), and curl-deleted the production volume and the volume-level backups in a nine-second chain (The Register, Apr 27 2026). Each individual turn was locally plausible. The chain was catastrophic. The four-tier matrix would have classified the action as Tier 4 and refused; the agent later admitted “I violated every principle I was given.” The principles were not wired into the substrate. That is a blast-radius failure, and it is the first SRE primitive because it gates everything else.
Detection signal: PreToolUse hook that asserts the planned action sits in its declared tier (substrate background in Claude Code Hooks: The Only Deterministic Substrate). PostToolUse hook that asserts diff size, files touched, and external calls stay under a session budget. The hooks are the circuit breakers; the budgets are the rate limits.
Primitive 2: Confidence threshold
A coding agent that never asks for help is not autonomous; it is unsupervised. The SRE primitive here is the confidence threshold: at what predicted likelihood of error does the agent pause, surface the choice, and wait for a human signal? HiL-Bench (arxiv 2604.09408, Apr 10 2026; revised May 4 2026) measured the gap directly: frontier coding agents (including Claude Code) “rarely invoke clarification mechanisms at the right time”; faced with unclear specifications, they fill gaps with confident assumptions and produce plausible but incorrect outputs without error, hedging, or escalation. The paper names three shapes: overconfident incorrect beliefs, high-uncertainty-yet-persistent errors, and imprecise broad escalation. The judgment is trainable via RL, but as of mid-2026 it is not the default.
The collaboration evidence puts a number on what the threshold buys. CentaurEval (arxiv 2512.04111, Nov 30 2025; revised May 21 2026; ICML 2026) benchmarked human-AI team performance on “collaboration-necessary” coding problems. Standalone LLM passed 0.67% of the benchmark. Human alone passed 18.89%. Human-AI team passed 31.11%. The 12-point lift over solo-human is the value of the threshold being calibrated; the agent that never escalates leaves it on the table.
No major vendor publishes a numeric confidence threshold for autonomous escalation. CodeRabbit’s trust framework (May 8 2026) names a seven-layer explainability model but discloses no internal confidence scores. Sourcegraph’s agentic coding post (May 21 2026) explicitly avoids probabilistic confidence thresholds and relies on deterministic code search plus mandatory human diff review. The only practitioner heuristic published is from an SRE piece (Anant Kumar, Nov 20 2025): increase agent autonomy when human reviewers accept 90%+ of suggested fixes; escalate immediately on unknown system states.
Detection signal: SubagentStop hooks that run an acceptance eval on the subagent output (schema check, golden-prompt diff, MCP-tool-call assertion) and forward decision: block if the eval fails. PostToolBatch hooks that block the next model call after a parallel tool burst when the burst hit a confidence threshold. The mechanism is the same as the silent-completion detection in Autonomous Agent Failure Modes; the SRE move is to call the eval a threshold, write the threshold into the runbook, and treat a missed escalation as a Sev event with its own retro template line.
Primitive 3: Runbook
A runbook in SRE is the document the oncall reaches for before paging. For coding agents, the runbook is AGENTS.md or CLAUDE.md in the repo root. They were not designed as runbooks; treating them like runbooks gives engineering teams the operational doctrine layer that vendor incumbents have not shipped.
AGENTS.md was formalised as an open spec in August 2025 through a collaboration of OpenAI, Google, Cursor, Factory, and Sourcegraph, and now appears in more than 20,000 public repos. CLAUDE.md predates it inside the Claude Code substrate. Both are loaded into the agent’s first turn the same way an SRE reads a runbook before responding to a page.
The SRE-shaped patterns are emerging from community practitioners, not from enterprise repos. The clearest examples are: Blake Crosley’s AGENTS.md patterns (Feb 28 2026), which use explicit “Never” lists (never delete files to resolve errors, never force push, never skip tests) plus a verification mandate (“Instructions without verification commands are suggestions, not rules”); HumanLayer’s good CLAUDE.md guide (Nov 25 2025), which keeps the file under 60 lines, moves task-specific docs into agent_docs/, and uses “Never send an LLM to do a linter’s job” as the boundary heuristic; and the OWASP secure-agent-playbook CLAUDE.md, the most SRE-adjacent public example, with preconditions (“always ask about context when ambiguous”), evidence mandates (cite CVEs, CWEs, OWASP refs), and a hard scope boundary (only /plugins/ directories). Stripe, Vercel, and Shopify do not publish AGENTS.md files with SRE-style escalation criteria as of May 2026; the pattern is community-led at the enterprise tier.
The four-section runbook shape, distilled from those examples:
- Preconditions — what the agent must verify before starting work; usually environment + state. (“Confirm working branch is not
main; confirm.remember/now.mdexists this session.”) - Escalation criteria — when to stop and surface a decision. Named failure modes (autonomous-agent-failure-modes), hard limits (max files touched, max external calls), and the “Never” list.
- Postconditions — what success looks like. The verification commands the agent must run before declaring done. Acceptance evals tie in here.
- Scope boundary — which files, paths, or repos are in-bounds; everything else is out.
Detection signal: a PreToolUse hook that asserts the agent has read AGENTS.md / CLAUDE.md this session (content hash) and that the file matches a known-good shape (the four sections present, line count under a budget). The hook is the equivalent of a PagerDuty rotation’s runbook freshness check; you do not let an oncall start without a current runbook, and you do not let an agent start without a current CLAUDE.md. The handoff between sessions (and between a previous agent and this one) is the same problem covered in The Agent Handoff Problem; the runbook is the artifact the handoff hands over.
Primitive 4: Escalation
Escalation in SRE is the routing rule that turns a signal into a page. For coding agents, the escalation substrate is Claude Code hooks (code.claude.com/docs/en/hooks). Twelve-plus lifecycle events map onto the routing decisions an SRE team would make.
The five hook events that carry oncall semantics:
- PreToolUse: the only pre-execution blocking point. Returns
permissionDecision: "deny"to block; works even when--dangerously-skip-permissionsis set. The PagerDuty equivalent is an alert filter that suppresses noise but never silences a real page. - SubagentStop: blocks subagent completion. The escalation point for fan-out work. Used in The Agent Handoff Problem as the handoff verifier; here it is the page trigger for “the subagent says done; the eval disagrees”.
- PostToolBatch: fires after parallel tool calls; can block the next model call with
decision: "block". The “throttle the agent before it does anything else” point. - TaskCompleted: blocks task completion, enabling rollback. The “revert before close” point.
- PostToolUse: the metric collection point. Diff size, files touched, scope budget consumed. Feeds the postmortem evidence pack later.
The escalation routing rule, in pseudocode, is the substrate-level mirror of a PagerDuty escalation policy. PreToolUse blocks Tier 4 actions outright; Tier 3 actions trigger a synchronous gate (page a human, wait); Tier 2 actions log and continue; Tier 1 actions run silently. SubagentStop runs the acceptance eval; TaskCompleted runs the verification commands from the runbook. The hook stack is the escalation policy.
The published practice tracks: pixelmojo.io (Feb 14 2026) documents PreToolUse as the security gate primitive, with file blocklists for middleware, auth routes, payment logic, environment files, and database connection settings. The post extends the pattern from “block bad actions” to “page a human when an action exceeds threshold”. The migration story from per-call permission prompts to capability tiers is covered in The Permission Prompt Is Dying; the hook escalation policy is what replaces the per-call gate.
Primitive 5: Postmortem
SRE postmortems live and die on three things: blameless timelines, MTTD/MTTR numbers, and action items tied to detection gaps. The Anthropic Apr 23 postmortem (2026) is the worked example because it documents an agent product (Claude Code) degrading for roughly six weeks before public revert, with no external pager path.
The timeline, read with an oncall lens:
- Feb 2026 — Opus 4.6 ships with
highreasoning effort as default. - Mar 4 — Reasoning effort silently changed to
mediumfor latency. - Mar 26 — Caching optimisation introduces a bug clearing session thinking every turn instead of once after idle.
- Early March — Customer-reported degradation begins.
- Apr 7 — Reasoning effort reverted to
high/xhigh. - Apr 10 — Caching bug fixed (v2.1.101).
- Apr 16 — Verbosity system prompt added; causes a 3% eval regression.
- Apr 20 — Verbosity prompt reverted (v2.1.116).
- Apr 23 — Usage limits reset; public postmortem.
MTTD math: roughly five to six weeks for the reasoning-effort issue between first reports and revert. For an SRE service this would be a Sev-1 with weekly executive reviews. For an agent product it lacked an automated detection path. The postmortem explicitly notes that “multiple human and automated code reviews, unit tests, end-to-end tests” missed the caching bug. The three overlapping regressions also masked symptoms from each other during investigation, extending MTTD further.
The remediations Anthropic added are SRE primitives in this post’s framing: soak periods, gradual rollouts, per-model system-prompt evals with ablation testing. Those are canary deployments and regression gates by another name. The framing matters because the team that names them by their SRE shape can borrow the existing tooling and rotation patterns instead of inventing new ones.
The closest published target framework comes from DigitalApplied’s MTTR/MTTD framework for agentic 2026 (May 12 2026): P0 detection under 5 minutes, P0 containment under 15 minutes, P0 MTTR under 2 hours, 70%+ automated detection, under 10% customer-reported. Aspirational, not measured, but worth naming because the Anthropic case missed every target.
Detection signal: a daily golden-prompt eval that runs the same prompt against the deployed model and compares output shape (length, structure, tool-call count) against a baseline. The same daily eval that catches the “model drift” failure mode in Autonomous Agent Failure Modes; the SRE move is to tie the drift signal to MTTD numbers and set a Sev threshold. Drift above threshold pages. The Anthropic case would have surfaced the regression in days, not weeks, because the per-turn caching truncation would have shown up as a shape change on day two.
How does a five-engineer agent oncall rotation work?
The five primitives compose into a rotation that runs without a vendor product. One engineer holds “agent oncall” for the week, owns the three runbooks (CLAUDE.md, AGENTS.md, postmortem template), and is the escalation target for hook-triggered pages. The substrate (hooks plus AGENTS.md plus evals) does the routing; the rotation is the human layer on top.
The minimum viable version is small. One repo, one CLAUDE.md, three hooks (PreToolUse, SubagentStop, TaskCompleted), one golden-prompt eval. Half a day to set up, half an hour a day to run. Less than the cost of one bad agent run. Cost discipline for the agent fleet itself lives in Agent Cost as a Team Sport and intersects this rotation at the postmortem step: every page should produce a token-cost line item alongside the MTTD number, because the cost of a bad agent turn is paid in API tokens before it is paid in revert time.
When isn’t Agent SRE the right answer?
Not every agent problem is an oncall problem. The five primitives are overkill if the agent runs only as a developer copilot (the human reads every diff before commit), if the repo is a personal project with no production deployments, if the agent fleet is one engineer’s sessions rather than a team’s pipeline, or if the “agent” is actually a single tool call in a deterministic pipeline.
Where this does apply: any team running agents unattended in CI/CD, agents that commit to default branches, agents that call external APIs with side effects, agents that span more than one repo, and multi-agent setups with subagents fanning out. The decision rule is one line: install the primitives the day the answer to “who would notice if the agent went sideways at 3 AM?” stops being “the human watching it.” The cost of running agents on the production codebase without an oncall path is a PocketOS in your repo; the cost of installing the runbook layer is half a day per team. The math is one-sided.
Agent SRE will not stop you from having bad agent runs. It will stop you from having silent bad agent runs, which is the precondition for fixing the substrate instead of arguing about the symptoms. The vocabulary borrowed from SRE works because the systems are isomorphic; the inversion of “AI SRE” into “Agent SRE” is the only naming arbitrage left in the category.
FAQ
Who pages when a coding agent goes sideways?
Whoever the team designates as agent oncall. The mechanism is the hook substrate (PreToolUse, SubagentStop, TaskCompleted) routing into the same channel the team already uses for service incidents (Slack, PagerDuty, GitHub issues). The page payload is the hook event plus the session context plus the proposed escalation. The substrate is in Claude Code Hooks: The Only Deterministic Substrate; the rotation is the human layer on top.
How do I cap blast radius for an autonomous coding agent?
Define four permission tiers (auto, async approval, real-time gate, hard disable) and map each tool, file path, and external call to a tier. Wire a PreToolUse hook that asserts the planned action sits in its declared tier. Anthropic auto mode (Anthropic Engineering, 2026) ships a 3/20 classifier baseline; the May 5 2026 tianpan piece codifies the four-tier matrix. Combine the two: classifier baseline plus explicit tier mapping in CLAUDE.md.
What does a runbook for an agent look like?
Four sections: preconditions (state verification), escalation criteria (when to stop, named failure modes, hard limits), postconditions (verification commands the agent must run before declaring done), and scope boundary (which paths are in-bounds). It lives in AGENTS.md or CLAUDE.md at the repo root and stays under ~100 lines per HumanLayer. Task-specific docs live in an agent_docs/ directory.
How long does it take to detect a misbehaving agent?
With no automation: weeks. Anthropic’s Apr 23 postmortem (2026) records roughly five to six weeks of MTTD on a caching bug plus a reasoning-effort downgrade plus a verbosity prompt. With daily golden-prompt evals plus hook-based scope budgets: under a day for most drift, real-time for blast-radius violations. DigitalApplied’s framework (May 12 2026) proposes P0 MTTD under 5 minutes as the target.
Are AGENTS.md files the new runbooks?
Yes, structurally. The pattern is community-led (Blake Crosley, HumanLayer, OWASP) rather than enterprise-led; Stripe, Vercel, and Shopify do not publish SRE-style AGENTS.md files as of May 2026. The gap between “open spec adopted in 20,000+ repos” and “operational doctrine adopted by enterprise repos” is the opportunity. The doctrine catches up to the format when the failures get expensive enough.
What this changes for the agents I run
Five primitives, five wires, one rotation. The next bad agent run has a Sev label, an oncall owner, and a postmortem template that fits on a single page. Most of the substrate is already in your repo: CLAUDE.md, the Claude Code hooks, the evals you already write. The Agent SRE move is to call them by their SRE names and treat the agent fleet as a service rather than a side experiment. The taxonomy in Autonomous Agent Failure Modes named the shapes; this post named the oncall. The cluster’s cost closer (Model Routing Economics, Wave 3 #16) closes the same loop one level up: routing decisions live above the runbook, but they pay for everything below it.
The category called “Agent SRE” did not exist on the 2026 SERP six months ago, and the products do not exist yet. The substrate does. Install one primitive this week. Pick the failure mode you saw most recently and wire its detection signal. Watch the next page arrive before the integration suite turns orange. The agent that runs your codebase is a service. Run it like one.
If it was useful, pass it along.
